Para realizar un pre-procesamiento correcto se combinaron los DataSet’s “MetaData” y “Reviews”; primero se trabajó con “Reviews”, este DataSet contiene la información de todos los comentarios de todos los productos de la subcategoría escogida y sus atributos se modificaron según:
-Se eliminan: reviewerID, reviewerName, Helpful, Summary, UnixReviewTime y ReviewTime
-Se mantiene: asin
Finalmente se trabaja con el atributo “ReviewText” del cual se obtienen las nuevas columnas:
-WordCountReview (cantidad de palabra del comentario)
-BlobPolarityReview (análisis de sentimiento: polaridad del comentario)
-BlobSubjetivityReview (análisis de sentimiento: subjetividad del comentario)
-VaderCompoundReview (representa un promedio compuesto de VaderPosReview, VaderNegReview y VaderNeutralReview)
-VaderPosReview (análisis de sentimiento: nivel de positivismo del comentario)
-VaderNegReview (análisis de sentimiento: nivel de negativismo del comentario)
-VaderNeutralReview (análisis de sentimiento: nivel de neutralidad del comentario)
Luego se trabajó con el “MetaData” este DataSet contiene la información de todos los productos de la subcategoría escogida y sus atributos se modificaron según:
-Se eliminan: title, imUrl, Brand y categories
-Se mantiene: Price
Luego se vio que salesRank era un diccionario que contenía la subcategoría a la que pertenecía el producto y el ranking de ventas pertinente; se procesó para que simplemente fuese un número. Finalmente related se convirtió en 4 columnas (correspondientes a los cuatro vectores que contenía este atributo), que contienen en forma de un entero la cantidad de elementos (productos) de los vectores also_bought, also_viewed, bought_together y buy_after_ viewing.
Después se unen estos DataSet’s pre-procesados utilizando el atributo “asin” y se obtiene un nuevo DataSet que ya no incluye ningún tipo de texto y solo tiene valores numéricos, amistosos con los algoritmos de clasificación y clustering. Ahora toca realizar la limpieza de datos; los datos sin precios y sin salesRank se eliminaron.
Nótese que el DataSet “Review” contiene aproximadamente un millón de datos mientras que “MetaData” contiene alrededor de cincuenta mil productos, el DataSet obtenido anteriormente se ordenó según los comentarios (un millón de datos) y se quiere un DataSet ordenado según productos (cincuenta mil datos), para esto se realizó un promedio normalizado de cada atributo con respecto a la cantidad de comentarios. Lo anterior resulta en un DataSet más pequeño de lo esperado a pesar de todo el tiempo de cálculo empleado en el pre-procesamiento (aplicar el análisis de sentimiento tomó aproximadamente 3 días); esto podría causar problemas a la hora de generalizar.
Con este DataSet se planea entrenar un clasificador con el fin de identificar productos exitosos, para esto se debe agregar un nuevo atributo, una clase, que indique si un producto es o fue exitoso en función de los comentarios y características del producto. Para lograr esto se obtuvieron los siguientes gráficos:
-Ranking: Buscando obtener un porcentaje de productos razonable, se buscó algún criterio de filtro que permitiera elegir una “elite” de productos exitosos, en este caso, se usó el Ranking (atributo “salesRank”) de los productos, mientras menor ranking más ventas. Observando este gráfico, poco se puede determinar pero dada la cantidad de productos se estimó razonable seleccionar los 15 mil productos con menor ranking, por lo que, se toman los productos con Ranking bajo 15 mil y se añade como criterio para determinar que un producto es “exitoso”.
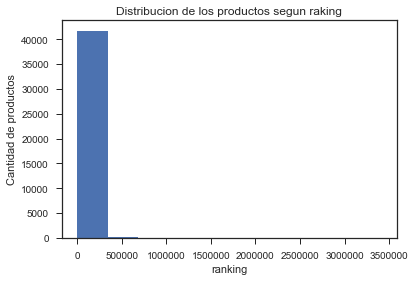 Gráfico 1: Distribución de los productos según Ranking.
Gráfico 1: Distribución de los productos según Ranking.
-Ranking (top 15 mil): Se grafica Ranking para los productos seleccionados, donde se aprecia una distribución, más o menos, homogénea.
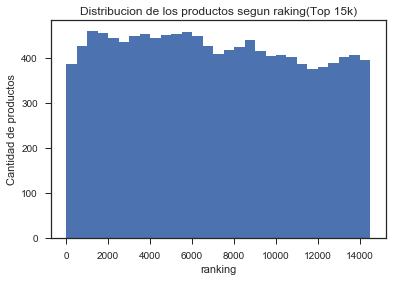 Gráfico 2: Distribución de los productos según Ranking (top 15 mil).
Gráfico 2: Distribución de los productos según Ranking (top 15 mil).
-Puntaje Overall: De este grafico se tomó la decisión de “Selecionar”, a los productos que tenían un Overall sobre 4.5, pues representa un porcentaje razonable de productos para etiquetar como “deseables” o “exitosos” dentro del universo ya acotado.
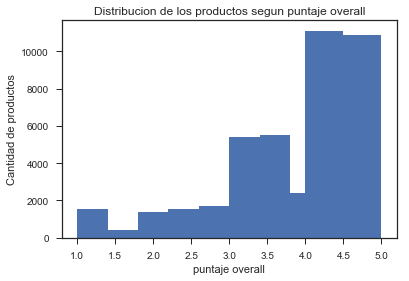 Gráfico 3: Distribución de los productos según puntaje Overall.
Gráfico 3: Distribución de los productos según puntaje Overall.
-VaderSentiment compound: Este es el criterio más interesante para seleccionar un producto “exitoso”, pues se basa –aplicando análisis de sentimiento sobre el texto- en el contenido promedio de los comentarios recibidos por este producto e indica el grado de negatividad-positividad del comentario, donde -1 es un comentario negativo y 1 es positivo. Para este criterio se determinó prudente seleccionar a los productos con un puntaje de 0.75 o mayor (comentario claramente positivo).
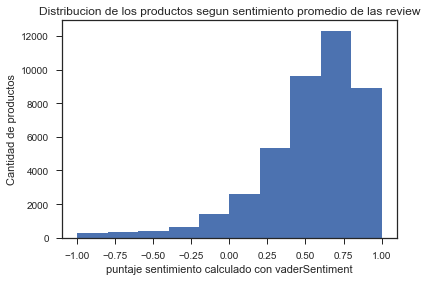 Gráfico 4: Distribución de los productos según VaderCompound.
Gráfico 4: Distribución de los productos según VaderCompound.
-Precio: Este grafico buscar responder la pregunta ¿Qué tan costosos son los productos exitosos obtenidos bajo los filtros aplicados?, se puede ver que ningún producto supera los 90 USD. Algo razonable al tratase de la categoría “VideoGames” y comprobamos que el ser exitoso, no implica ser caro (al menos en esta categoría).
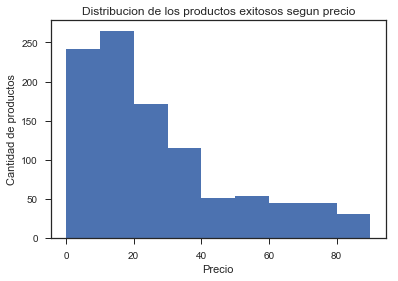 Gráfico 5: Distribución de los productos exitosos según precio [USD].
Gráfico 5: Distribución de los productos exitosos según precio [USD].
En resumen, los productos “exitosos” son seleccionados según; Overall ≥4.5, Ranking≤15k y VaderSent. ≥0.75 y se etiquetan en un nuevo atributo (Clase objetivo) por 1 y el resto de los productos se etiqueta con 0, de modo que los productos exitosos están representados por 1 en la clase y los productos normales (no exitosos) por 0. Luego se realiza una limpieza de datos, o sea, se eliminan los productos que tienen datos en blanco o los datos inútiles, también fue necesario eliminar 3 atributos, estos son; “Overall”, “salesRank” y “VaderCompound” con el fin de que el clasificador que se quiere entrenar no reconozca los criterios utilizados para elegir a los productos “exitosos” y reconozca patrones en el resto del análisis de sentimiento, patrones que un ser humano no podría encontrar en una base de datos de este estilo. Cabe mencionar que no fue necesario eliminar OutLayers, ya que para seleccionar a los productos interesantes se utilizaron “filtros” basados en relaciones de orden, por lo que se “comería” a cualquier OutLayer, simplemente se eliminaron atributos innecesarios, como ya se indicó más atrás.
El DataSet final obtenido -la que incluye la clase objetivo- es apropiado para entrenar a un clasificador, pero por la naturaleza del problema y el pre-procesamiento efectuado, la clase objetivo presenta un fuerte desequilibrio, es decir, hay más elemento etiquetados con 0 que con 1, tal que se cumple (N° de Productos con clase 1)/(N° de Productos con clase 0) = 0.0298. Para solucionar este problema se aplicó OverSampling en 1, resultando; (N° de Productos con clase 1)/(N° de Productos con clase 0) = 0.967 y SubSampling en 0, obteniéndose; (N° de Productos con clase 1)/(N° de Productos con clase 0) = 1.127.
Luego se procedió al entrenamiento del calificador con los DataSets obtenidos –el original, el con OverSampling y el con SubSampling-, y para el testeo de este, se reservó el 30% del DataSet utilizado para entrenar al clasificador (este porcentaje no se utilizó en el entrenamiento) con el fin de realizar el testeo del clasificador obtenido. Para cada DataSet se entrenaron 4 clasificadores – KNN N=5, Decision Tree, Gaussian Naive Bayes y Base Dummy (stratified)- a los que se le calcularon el “Score”, “Recall” y “Precision”, se muestra el Score en los siguientes gráficos (para distintos grados de OverSampling y SubSampling).
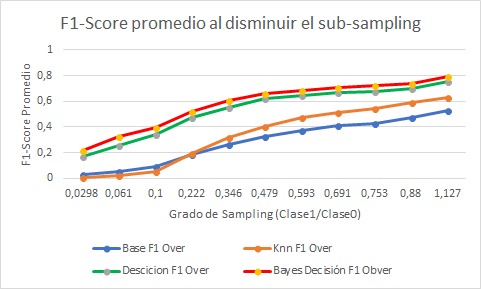 Gráfico 6: Score promedio al disminuir Sub-Sampling.
Gráfico 6: Score promedio al disminuir Sub-Sampling.
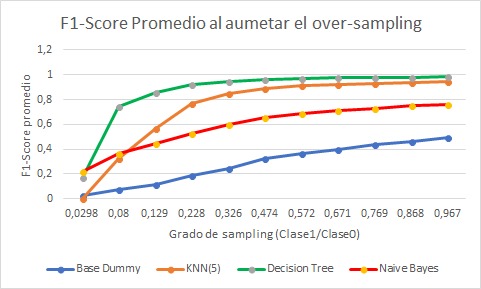 Gráfico 7: Score promedio al aumentar Over-Sampling.
Gráfico 7: Score promedio al aumentar Over-Sampling.
A continuación se muestra una imagen detallada de los resultados obtenidos:
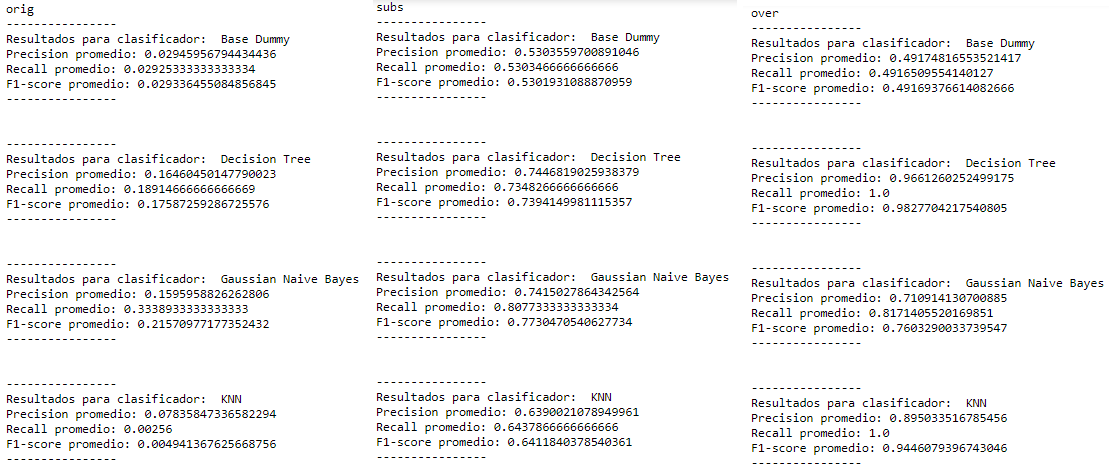 Foto 3: Resultados obtenidos.
Foto 3: Resultados obtenidos.
A continuación se muestra una imagen que muestra los atributos del DataSet final (post filtro):
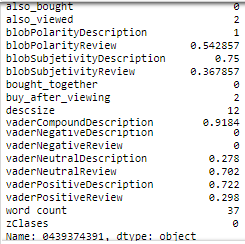 Foto 4: Atributos DataSet Final.
Foto 4: Atributos DataSet Final.