Consideraciones c/r Hito 1
Uno de los comentarios que más se repitió después de la presentación del hito 1 fue la falta de gráficos obtenidos a partir de los datos, por lo que en esta ocasión se añadieron múltiples gráficos, con el fin de hacer más dinámica la presentación.
Otro comentario útil que se rescató fue “aclarar bien los atributos de los DataSet’s y destacar los atributos útiles”, esta consideración se puede apreciar en la pestaña Procesamiento donde se explica cada atributo como se trabajó con ellos, en particular los más importantes.
Otro problema fue la poca claridad de la motivación de nuestro proyecto, por lo que esta fue reformulada y replanteada.
Análisis de resultados Hito 2
Los resultados obtenidos para cada clasificador fueron medianamente satisfactorios para los clasificadores con Over y Sub Sampling, sin embargo los que presentaron mejor desempeño fueron; Decision Tree, Gaussian Naive Bayes (Sub-Sampling) y Gaussian Naive Bayes (Over-Sampling), con métricas que rondan el F1-score = 75% a pesar de que existen clasificadores con mejores resultados (cerca del 95% 0 100%), estos son sospechosos y probablemente poco generalizables. Por esto se considera para el Hito 3; probar distintos grados de Over y Sub Sampling con el fin de obtener mejores resultados.
Hito 3: Validación de los clasificadores
Para el Hito 3 se planteó la pregunta, ¿estarán funcionando correctamente los clasificadores?, y para responderla se barajaron dos posibles problemas; la primera fuente de error o mal funcionamiento de los clasificadores se puede deber a que los productos etiquetados como exitosos no son, todos, realmente exitosos y la segunda a que puede existir una fuerte dependencia de solo un par de atributos que distorsionan los resultados.
Para verificar la primera idea recién planteada se revisaron los resultados entregados por el criterio de selección de un producto exitoso, para esto se tomaron muestras al azar de esta selección y se comprobaron los números de ventas (Foto 1), criticas profesionales (Foto 2) y de usuarios sobre el producto (Foto 3), esta informacion fue obtenida de los sitios Metacritic[2] y VGChartz[3], el hecho de que el DataSet utilizado fuese de videojuegos, facilitó esta tarea aunque el hecho de que no todos los productos de esta categoría correspondiesen a videojuegos mermó un poco el desempeño, los resultados de esta exploración se aprecian a continuación.
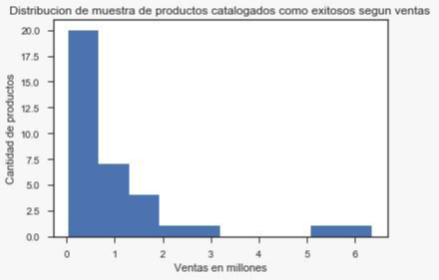 Foto 1: Distribución de ventas por millón de muestra de los productos etiquetados como exitosos.
Foto 1: Distribución de ventas por millón de muestra de los productos etiquetados como exitosos.
Observando la foto anterior se puede ver que la mayor cantidad de los productos muestreados presenta una tasa de ventas, relativamente, baja.
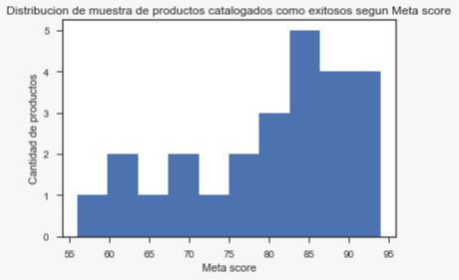 Foto 2: Distribución de puntaje según Meta Score de muestra de los productos etiquetados como exitosos.
Foto 2: Distribución de puntaje según Meta Score de muestra de los productos etiquetados como exitosos.
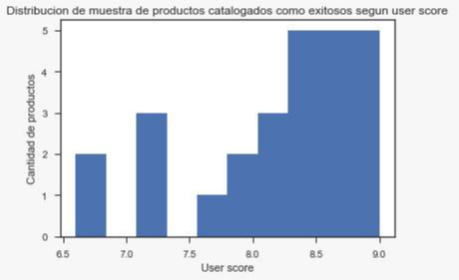 Foto 3: Distribución de puntaje según User Score de muestra de los productos etiquetados como exitosos.
Foto 3: Distribución de puntaje según User Score de muestra de los productos etiquetados como exitosos.
Con los últimos dos gráficos se puede ver que, en general, los productos muestreados presentan buenas críticas, tanto de los usuarios como de los profesionales, esto tiene sentido pues una de las métricas utilizadas para filtrar es la valoración de los usuarios, los mismos jugadores, y estas tienen cierta similitud con la opinión de los profesionales, estos últimos indican las tendencias.
Finalmente se puede deducir que si bien el criterio selecciona juegos bien valorados por los consumidores, no son necesariamente un éxito de ventas. Con lo que se comprueba la existencia de un problema en el criterio de selección de la clase a clasificar, lo que conlleva un mal clasificador.
En resumen, en promedio los productos no son exitosos en ventas, las críticas tenían BIAS, ¿Por qué ocurrió esto? Porque no se aplicó un filtro correcto a los datos, para tener mejores resultados un experto debería etiquetar cada producto, otra posible causa de que los productos seleccionados no tuviesen el éxito esperado es la insuficiencia de datos, tal vez con un DataSet más actual se puedan lograr mejores resultados.
Por otro lado, para comprobar la segunda hipótesis antes planteada, se procede a observar el efecto de cada atributo en las métricas del clasificador obtenido, para esto se retiran atributos o conjuntos de atributos y se ejecutan los distintos clasificadores para Over y Subsampling, obteniéndose las siguientes métricas:
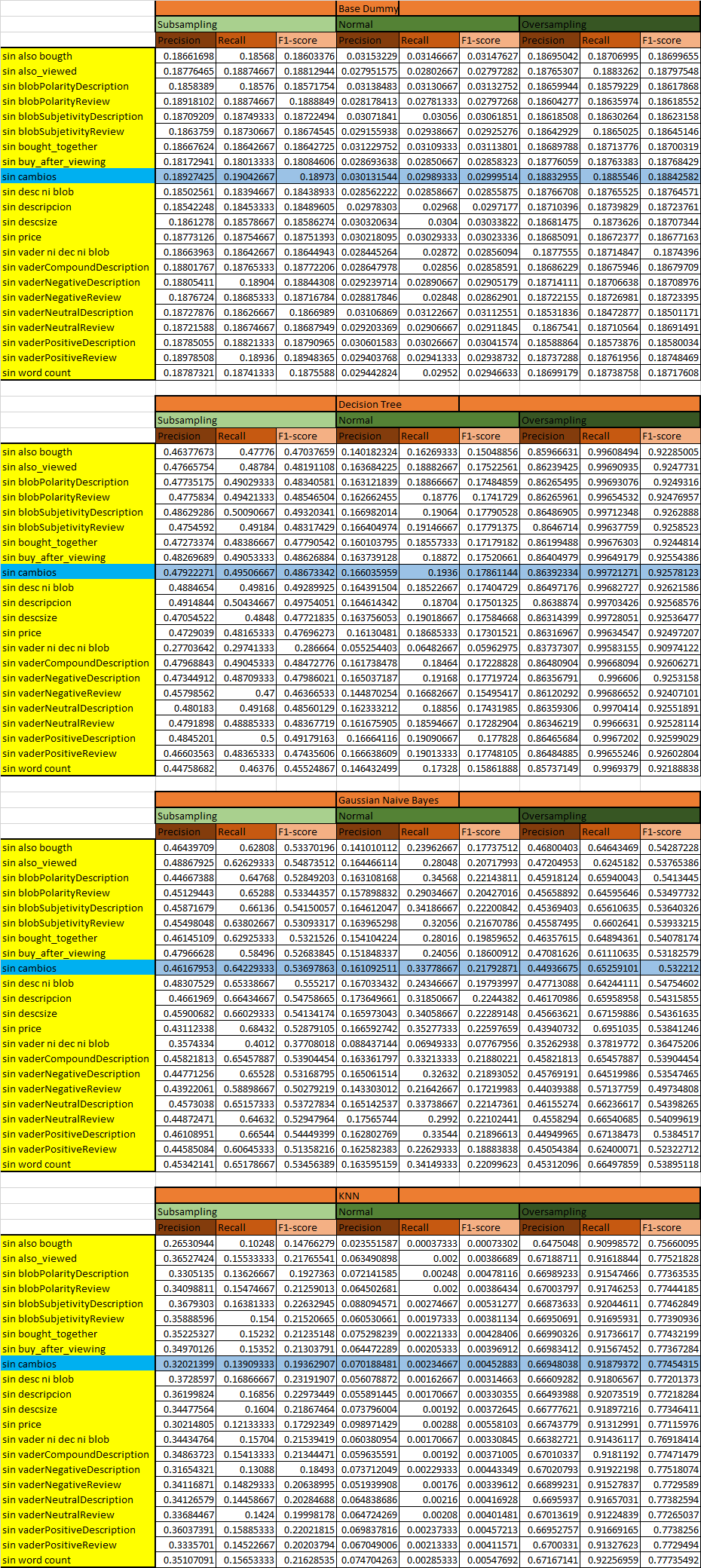 Foto 4: Tablas de métricas para cada clasificador creado.
Foto 4: Tablas de métricas para cada clasificador creado.
Observando esto es difícil saber si un clasificador resulta mejor/peor que el caso base (fila celeste), para tener una mejor visualización se efectúan 4 tablas nuevas, sin la fila del caso base, estas tablas corresponden a las métricas de los nuevos clasificadores menos el caso base, es decir cada fila se resta con la fila del caso base y se dejan en blanco los cuadros que presentan poca variación en magnitudes, en celeste los que presentan variación positiva y roja la negativa, esto se puede apreciar en la Foto 5.
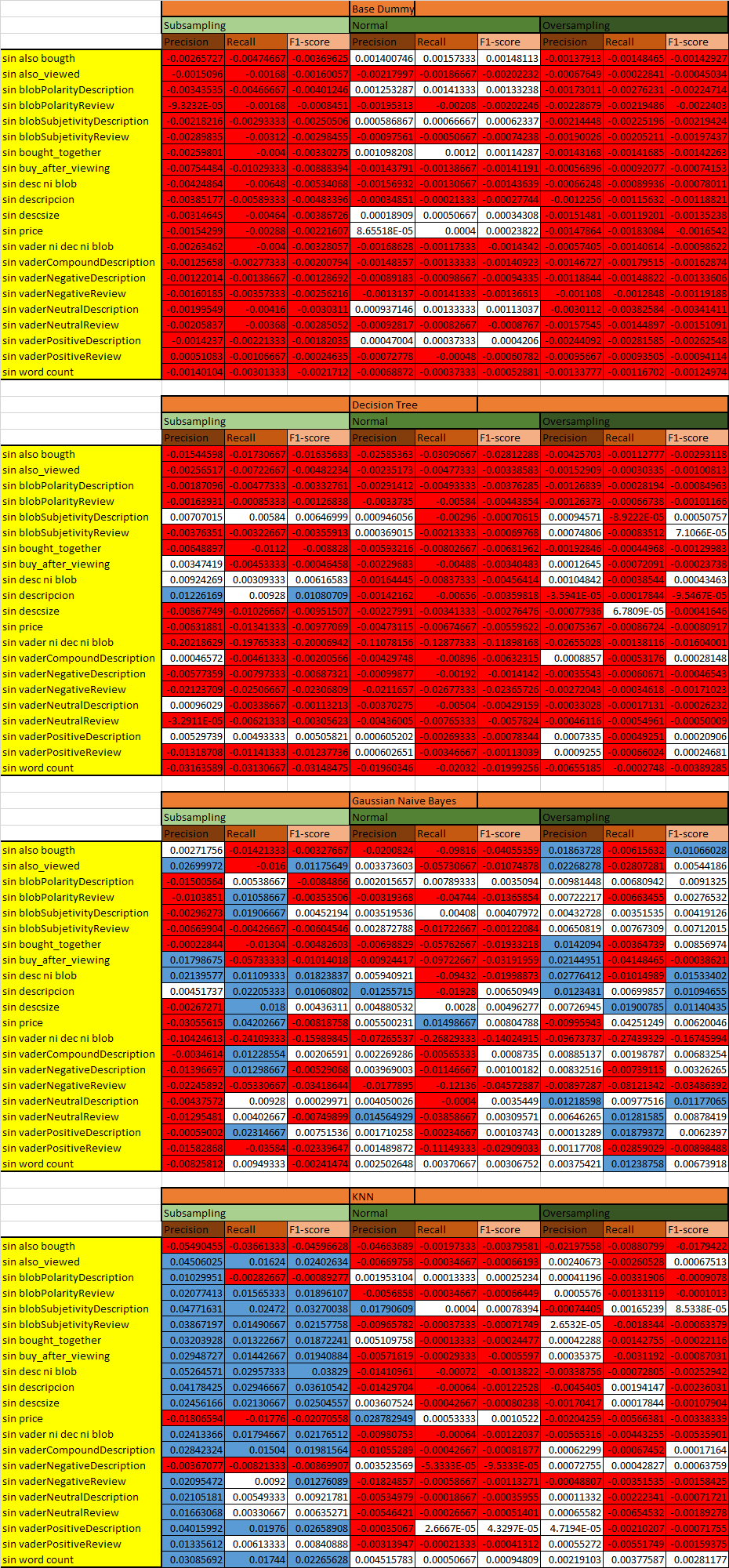 Foto 5: Tablas de comparación de métricas c/r al caso base para cada nuevo clasificador creado.
Foto 5: Tablas de comparación de métricas c/r al caso base para cada nuevo clasificador creado.
Del grafico de la Foto 5 se concluye que atributos afectan más a cada clasificador; para Decisión Tree estos son Price, Desc. Size, Blob sent. Review, Word Count y por sobre todo Related y sus ausencias provocan una disminución en las métricas de este clasificador en general. Para KNN ocurre lo mismo, bajan sus métricas, excepto para el caso de Subsampling, y los atributos que lo afectan son; Vader, Desc. Size, Blob sent. Review y, el mas importante, Also Bought. Finalmente en Bayes se observan subidas y bajadas, es más irregular, y las variables que más le afectan son; Related y los más importantes; Vader, Desc. Size y Blob sent, review.