Hito 2
Se presenta el trabajo hecho hasya este momento, el avance en los objetivos y algunos avances en sistemas de clasificación
Introducción
Mediante este informe se presentan los avances en el desarrollo del proyecto del curso de "Introducción a la Minería de Datos", el cual trata de poder entregarle las mejores recomendaciones de cuidado para mascotas a las personas que pertenezcan a la red social de mascotas "FacePet". En específico, para el trabajo se intentarán sacar las mejores recomendaciones segun fotos de perros.
Se presentarán a continuación la motivación de este trabajo, el fin que se busca, el análisis de la base de datos que se nombró con anterioridad en el Hito 1 y cierta aplicación de algunos algoritmos implementados para el análisis del problema.
Finalmente, se analizarán los resultados obtenidos, tanto de los métodos de Cluster usados como del preproceso de las imágenes del dataset, además de analizar el trabajo futuro que toca en el proyecto.
Motivación
Cuando una persona tiene una mascota, es porque uno elige que esta sea parte de la familia, por lo cual es un deber y una preocupación darles el cariño y la atención que se merecen, no solo porque sean nuestras mascotas, sino que tambien porque son parte importante de nuestras vidas, nos ayudan tanto en las energías del día a día, te animan y te dan cariño incondicional que puede sacar más de una sonrisa.
Por estas razones y por muchas otras más, hay mucha gente que ama a sus mascotas y darían cualquier cosa para poder hacerlas feliz y hacer que estén lo más comodamente posible. Hasta hay gente que ingresa a sus mascotas a un facebook de perros, llamado 'facepet', en la cual ellos pueden subir fotos, publicar eventos y conocer a otros dueños de mascotas, para que estas se hagan amigas y jueguen muy felices.
Para poder entregar los mejores cuidados a las mascotas, nosotros proponemos un sistema que pueda analizar las fotos de las mascotas, en este caso de perros, pueda extraer las característas más importantes de las imágenes, así luego ofrecer a los usuarios los mejores productos para su perro, los cuales podrían ser articulos de aseo, como shampu, cepillos u otros elementos, articulos de juegos, entre otros.
Análisis de los Datos
Para el caso a analizar se usa el mismo DataSet antes usado, de las imágenes de perros y sus razas de la Universidadde Stanford, ya que la página de facepets está en fase beta y no encontramos las imágenes de esta página. Aún así, cabe destacar que las imágenes del DataSet usado y de la página web a analizar son muy parecidos, con imágenes de perros jugando, fotos con sus dueños y en otras actividades, las cuales pueden influir por el ruido que estas tienen.
Inicialmente, como medida de prueba, se decidió cortar el dataset e 120 clases a 20 clases, con las primeras clases del dataset, las cuales constaban de uno aproximado de 180 imágenes por clases. Dentro de esta cantidad de datos se encontraban imágenes de todo tipo, las cuales deben ser filtradas, para hacer que los algoritmos que vamos a usar funcionen sin ruido. Este proceso, que para el caso de esta parte del trabajo se esta haciendo de forma manual, la idea sería que se haga de forma automática, asi evitar problemas y que la intervención del humano sea la menor posible. Cabe si destacar, que aunque sería lo ideal, no se propone como parte del trabajo de este proyecto.
Inicialmente, se procede a eliminar las componentes de las imágenes que pueden interferir en el algoritmo. Como se ve en la figura a continuación, en el caso de las imágenes que tenían algún distractivo muy llamativo, como el perro robot de la figura, fueron recortados, para evitar confusiones en el sistema.

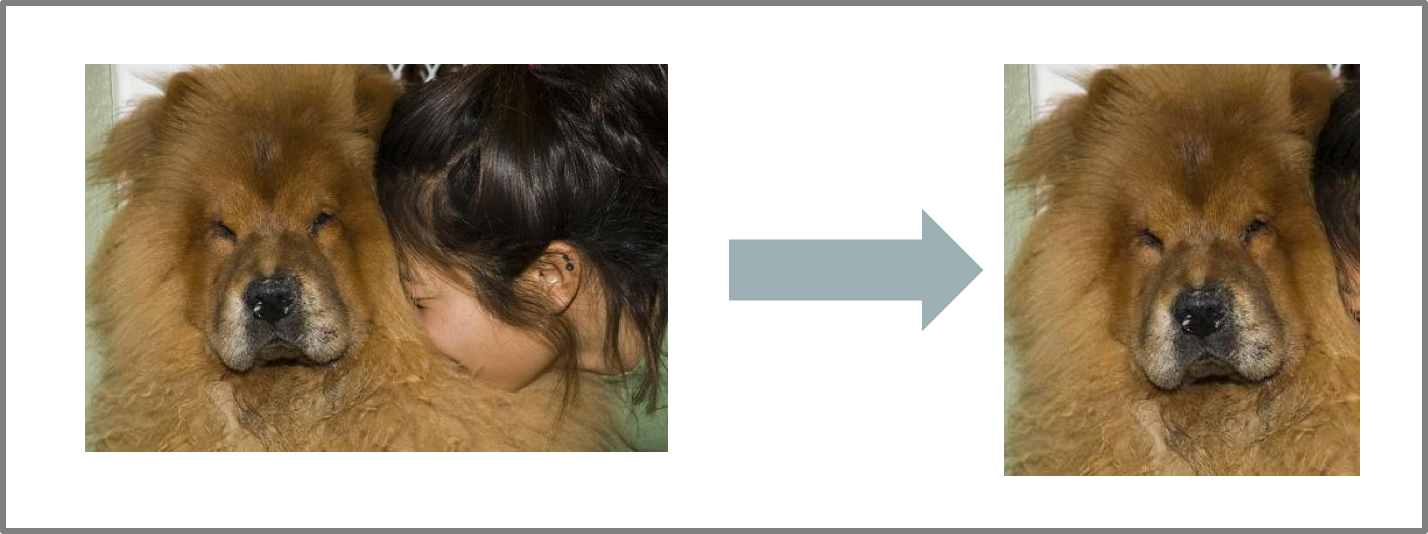
Por otro lado, al ser mascotas, no faltaban las imágenes en las cuales, además de salir el perro en cuestion, podría salir su dueño o algún humano en la imagen. Como nosotros no queremos a los humanos, solo a los perros, fueron recortados de las imágenes, como se puede observar en la siguiente figura.
Por último, se encontraron imágenes en las cuales había mucha interferencia en ellas, ya sea porque salían muchos perros, existían filtros en las imágenes o salían en actitudes en las cuales no se podría ditinguir de gran manera cual era el foto de la foto. Es por esto que estas fotos fueron removidas y guardas, por si en algún futuro se fueran a usar. Un ejemplo, es la figura que sale a continuación.

Posterior a este filtrado, el cual fue hecho a mano, se procedió a la realización de un 'risize' de todas las imágenes del dataset, transformándolas todas al tamaño 140x140, esto por la grán diversidad de tamañosque existían. Esto se hizo en Jupyter, y el código se puede encontrar acá.

Ahora, por otro lado, se decidió analizar de manera incial, analizar sin ningún tipo de preprocesamiento las imágenes. De esta forma, lo primero que se viene a la mente es analizar las imágenes según el valor de sus pixel en los tres espectros que entregan las imágenes digitales RGB, y ver que se obtenía de su distribución. A continuación se presenta un histograma que contiene la agrupación de los pixeles según los colores de cada imágen. Como se obtuvo esta imagen fue utilizando el programa Jupyter, y el código se encuentra en este link.
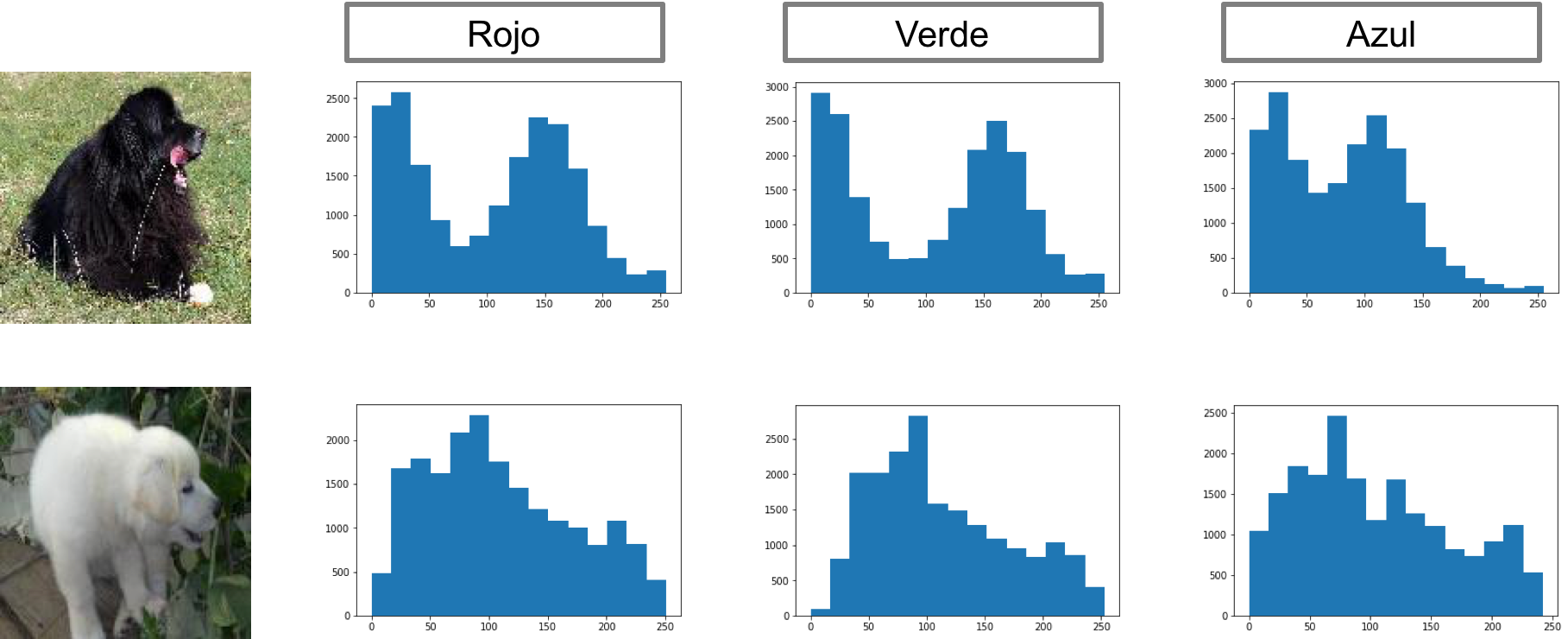
Como se puede observar de esta figura, existe una diferencia en la distribución de los colores de las imágenes, dando una cantidad de color en ciertas zonas, con respecto a otras. Esto nos puede dar una idea que analizar el color de las imágenes puede ser un método útil.
Es por esto, que durante el trabajo realizado en esta sección, se trabajará con un vector de todos los datos de los pixeles de las imágenes. Este será el input de todos los sistemas a analizar. Su gran problema si, es la dimencionalidad, ya que el vector será del tamaño 140x140x3.
Esquema de Trabajo
El esquema de trabajo se muestra en la imagen de a continuación. Este esquema separa en cómo se trabajará la imagen inicialmente, para así preprocesarla y clusterizarla utilizando distintas metodologías abordando el mayor espacio de algoritmos posibles.
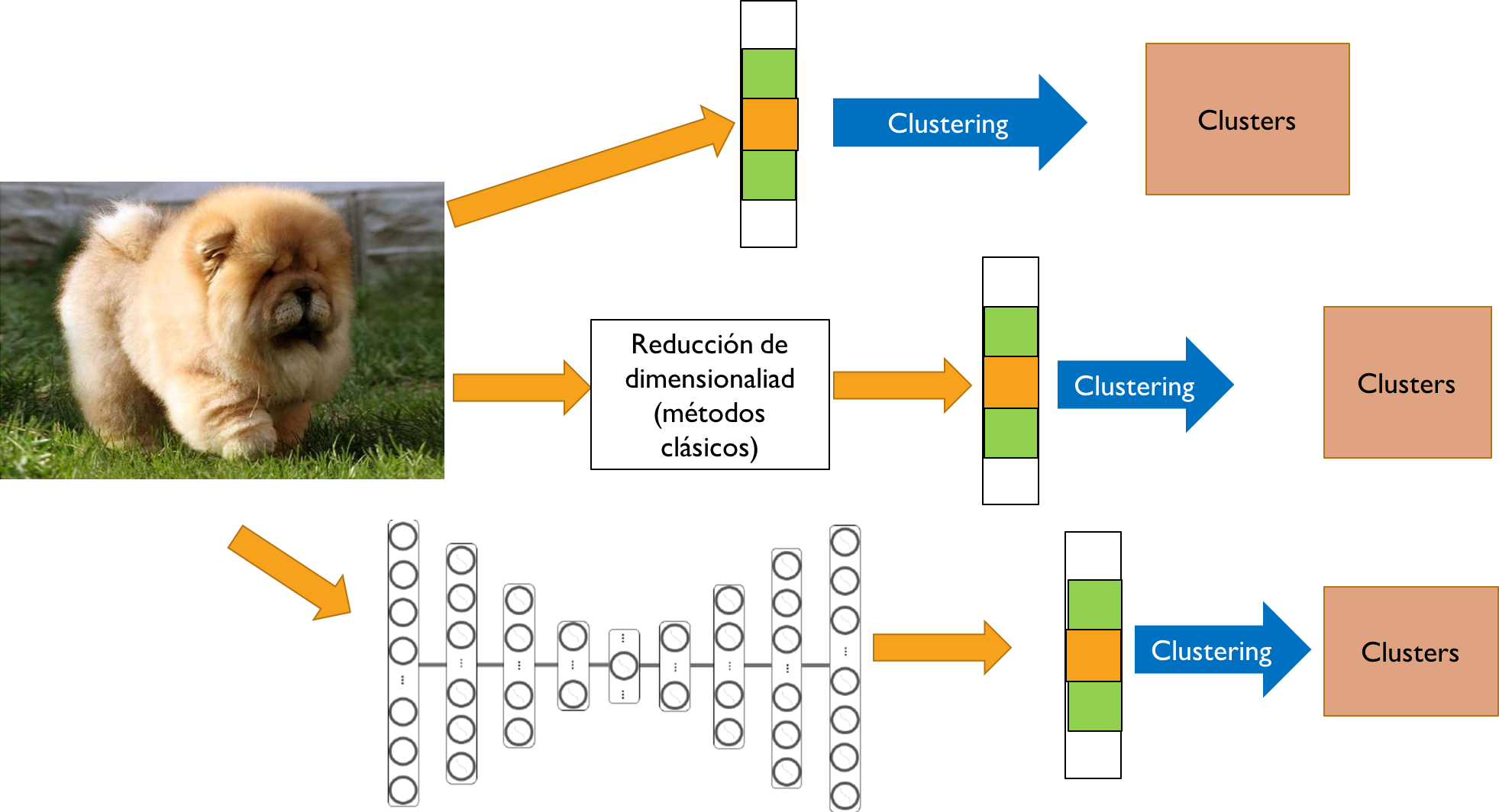
- La primera opción corresponde, a estirar la imagen. Estirarla quiere decir que el dato inicial no es una matriz con ancho y alto sino un vector. Este vector posterior se clusteriza utilizando métodos clásicos de agrupamiento.
- La segunda opción se basa en preprocesar la imagen con técnicas de reducción de dimensionalidad, por ejemplo PCA, aunque también no se descartan otras técnicas que pueden particularmente útiles para imágenes como HOG o SIFT. Las características obtenidas por este preprocesamiento se le aplican métodos de clusterización clásicos.
- La tercera opción es similar a la segunda, se busca obtener por métodos de preprocesamiento reducir la dimensionalidad de la imagen de input. La diferencia con el punto anterior es que en este caso el preprocesamiento es utilizando redes neuronales, esto se realiza mediante un autoencoder. El autoencoder es un tipo de red neuronal que intenta aprenderse la imagen de input pero pasando por capas intermedias que tienen una baja dimensión, de este modo estas capas intermedias alojan mucha información porque son necesarias para realizar la reconstrucción de la imagen, estas capas pueden ser utilizadas entonces para clusterizar utilizando métodos clásicos.
Agoritmos de Pruebas
Para empezar el análisis de los datos mediante métodos de clustering, cabe destacar que en este punto se está trabajando con los datos en bruto, esto implica, que las imágenes solo están transformados en un vector, sin preprocesamiento previo ni proceso en el cambio de la dimensión. Por esto, los métodos que se revisaran a continuación son proceso previo para tantar el terreno, más que un método más eficiente.
Los algoritmos ha realizar son los puntos explicados en el esquema.
- K-MEANS
- Clusting Aglomerativo
- Autoencoder
Para este trabajo, se tomaron 3 clases de perros de la base de datos al azar, y se realizó un entrenamiento de clustering usando la herramienta de k-means que entrega scikit-learn sobre estos datos. La idea de este proceso es, pasandole 3 razas de perros al sistema y perdirle al algoritmo que entregue los datos separados en 3 grupos, si es posible para el separarlos en las clases originales.
Para esto, se le pide al algoritmo que haga el clustering correspondiente, y se hace el match entre el label entregado por K-means y el original de la imagen. Haciendo esto, se puede encontrar que el valor obtenido de accuracy es de 46,2%. Idealmente no es bueno, aún así está sobre el promedio de la selección aleatoria. Cabe destacar si, que las imágenes al tener tantas dimensiones, k-means pierde eficiencia, por lo que para futuro trabajo se necesitan disminuir las dimensiones.
Si desea ver el código utilizado, se puede encontrar el código acá.
De la misma forma que en el proceso anterior, se procede a entrenar la red con 3 clases de perros al azar de la base de datos. Se usan estas imágenes tambien sin preprocesamiento, sino que tambien solo los datos están transformados en un vector con todos los pixeles.
Por otro lado, para el entrenamiento de este clustering también se usa la función de agglomerative clustering de la librería scikit-learn. Para este caso, se entrena con las 3 opciones que ofrece el sistema, ward, average y complete, que son 3 métodos distintos para medir las distancias del sistema. Los resultados obtenidos luego de este trabajo se pueden observar en la siguiente figura.
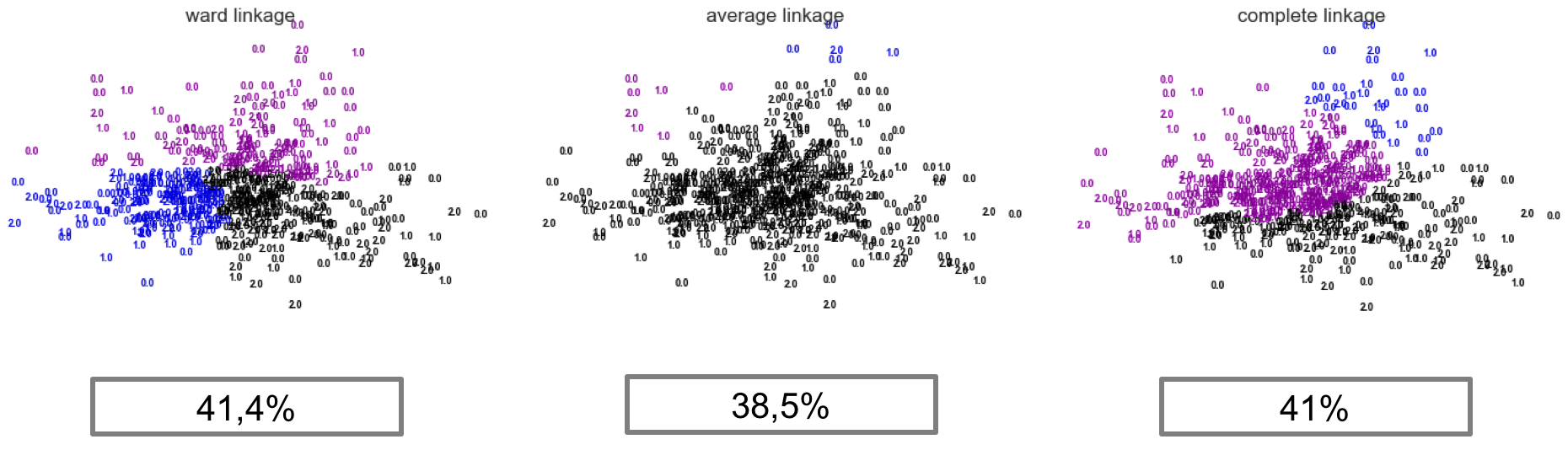
Debajo de cada diagrama se puede encontrar el valor del accuracy de cada método. Cabe destacar que al igual que el método anterior, se hace el match entre el label entregado por el algoritmo para imagen con el match original.
Se puede observar de estos valores que son menores que k-means, la gran causa, la gran dimensionalidad de los datos, los cuales se deben bajar en un futuro trabajo, para luego ver si se mejoran mejor los datos. Si se desea er el código utilizado, se puede observar en el siguiente link.
Uno de los "aproach" que se realizó en esta entrega es la utilización de redes neuronales. Como se explicó anteriormente un autoencoder permite obtener características relevantes mediante la utilización de capas de baja dimensionalidad. La arquitectura se puede encontrar en el jupyter notebook adjunto en donde se implementó la red.
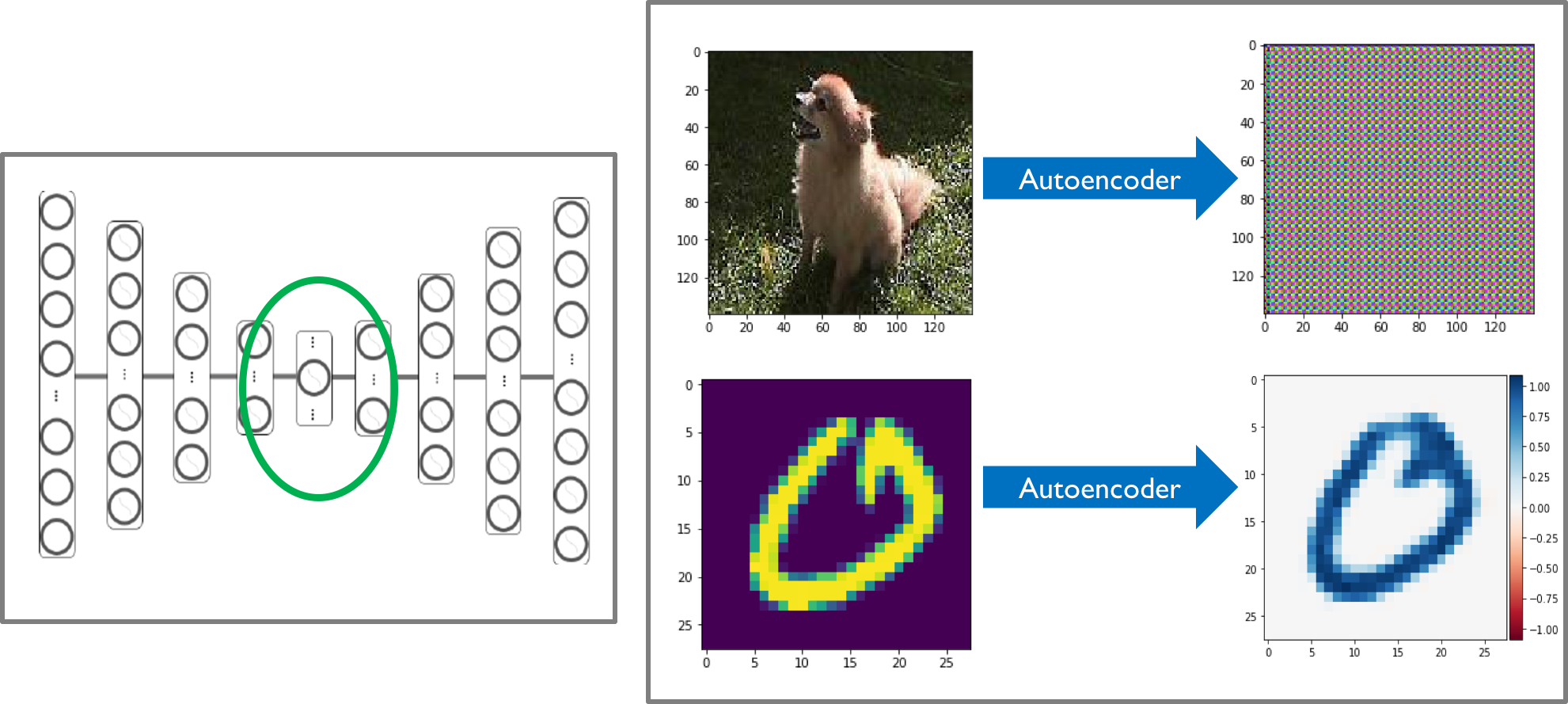
A la izquierda de la imagen se puede observar un esquema de un autoencoder con un círculo verde indicando las características que pueden ser de utilidad para la clusterización.
A la derecha de la imagen se puede se observar los resultados obtenidos. Notar que la reconstrucción de la imagen de un perro no se logró adecuadamente, uno de los motivos principales es que la imagen es de muy alta dimensionalidad para la tarea requerida, falta realizar estudios de redes neuronales para ser posible una adecuada implementación. Como se puede observar si se logra reconstruir un dígito manuscrito la cual es una imagen de 28x28 por lo que es posible realizar la tarea y se debe estudiar de mejor manera el tema. El código utilizado para este trabajo se puede encontrar acá.
Trabajo Futuro
A continuación se muestra el trabajo futuro en donde se observa las posibles tareas a realizar y estudiar con mayor detalle.
- Cambiar tamaño de las imágenes dataset: Uno de los puntos más notorios en los resultados tanto de cluterización como obtención de características con el autoencoder, es que la imágenes de $140 \times 140$ son de muy alta dimensionalidad para tratarlas de este modo, se requerirá hacerles un "resize" para trabajar con una menor dimensión.
- En el esquema propuesta so muestra que se realizará un preprocesamiento de imágenes utilizando métodos clásicos para imágenes, HOG, SIFT, PCA etc. Esto sería útil para reducir dimensionalidad y obtener características más relevantes.
- Se perfeccionarán los algoritmos utilizados, muchos de estos tienen hiperparámetros que se utilizaron por defecto y realizar un ajuste apropiado puede implicar mejores resultados.
- Un cambio de dataset no se descarta, si utilizando los ajustes mencionados anteriormente no se mejora en porcentaje adecuado los resultados, es posible un cambio de dataset donde el nuevo sea más numeroso e inicialmente de menor dimensión y además de que cualitativamente pueda ser más sencillo.
- Finalmente y el punto más relevante de nuestro proyecto es analizar las características, es decir observar cuales son los cluster y que tiene cada cluster para así cumplir el objetivo de obtener características relevantes que puedan ser utilizadas posteriormente en mercados (Facepet) para detectar gustos.