Hito 1
A continuación se presenta un pequeño reporte del trabajo hecho durante el hito 1.
Introducción
El presente informe tiene por objetivo introducir el proyecto que realizarán tres alumnos de pregrado en el contexto del curso CC5206, "Introducción a la Minería de Datos", durante el semestre de primavera de 2017. Se abordará la temática central de trabajo, las hipótesis relevantes que se deseen validar y la forma en que se dará solución a la problemática establecida.
En particular se trabajará con metodologías de clustering aplicado a imágenes de una base de datos de la Universidad de Stanford que contiene más de 20.000 fotografías de perros, clasificadas según la raza del animal en 120 categorías. En principio se encuentran diversas dificultades que vuelven al proyecto una actividad desafiante que se espera poder atacar adecuadamente con los conocimientos que se adquieran durante el semestre.
Temática o problemática central
La temática de este trabajo se desarrolla en el entendimiento y aplicación de algoritmos no supervisados para establecer cómo los datos distribuyen y cómo estos pueden ser agrupados. El proyecto que se desarrollará a lo largo del semestre estará enfocado en el clustering de datos, identificando así las agrupaciones obtenidas y las que son más cercanas entre sí. Finalmente se interpretará las características que son relevantes en el desarrollo de los clusters.
El clustering es relevante en el contexto de machine learning ya que permite de una manera no supervisada establecer agrupaciones que pueden ser de interés o utilidad económica para el que las usa, ejemplos de estos son variados, los ejemplos más conocidos en la actualidad es en la agrupación de gustos o sistemas recomendadores tales como los que utiliza Amazon o Netflix. Cabe recalcar que la ventaja fundamental de los algoritmos no supervisados es que estos se pueden utilizar cuando los datos no están etiquetados pudiendo analizar los datos tanto cualitativamente como cuantitativamente sin tener un gran conocimiento del dataset analizado.
El dataset que se utilizará al menos en un comienzo, es un dataset de perros en donde se realizará un clustering para poder encontrar las razas que en este dataset se encuentran. El problema principal de esta tarea es que el dataset es de imágenes de alta calidad pudiendo llegar el vector de características a un número de 20.000 dimensiones en ocasiones. Métodos clásicos de reducción de dimensionalidad como PCA son demasiado limitados e incluso lineales para poder resolver un problema de esta índole, además algoritmos de clusterización clásicos también sufren de suposiciones demasiado fuertes (K-means o hierarchical clustering).
Debido a lo explicado anteriormente nace la necesidad de utilizar algoritmos con una matemática más robusta y que puedan resolver problemas de alta dimensión como es el caso de la tarea presentada. Es por esto que se resolverá el problema utilizando redes neuronales profundas, en particular se utilizará un método llamado variational autoencoder (VAE) el cual tiene extensiones para poder utilizarlo como un algoritmo de clustering, la idea principal de este algoritmo se explicará brevemente más adelante.
Los pasos iniciales es realizar clustering utilizando estos métodos clásicos como K-means con PCA, etc. Posteriormente se utilizarán algoritmos basados en redes neuronales profundas, en este caso es el VAE. Este algoritmo funciona de manera similar a un autoencoder, donde se viaja a desde una alta dimensionalidad hasta una baja dimensionalidad (variables latentes) y desde esta baja dimensionalidad se intentan reconstruir los inputs (o el dataset de alta dimensionalidad). Las ventajas de estas variables latentes son directas, estas variables de baja dimensionalidad son la compresión de las características más importantes del dataset, por lo tanto realizar clustering en este espacio es más sencillo. Finalmente se utilizarán extensiones del VAE para poder realizar clustering más adecuados.
Análisis de DataSet
Para el trabajo de clasificación de imágenes, se ha elegido un dataset abierto y de libre acceso. Este dataset se encontró en la página de la universidad de Stanford, y consta de una base de fotos de razas de perros de varios lugares del mundo. Se puede acceder a los datos a través de la siguiente página web.
La base de datos consta de 120 clases con un total de 20.580 imagenes. Pero, lamentablemente estos datos no son tan regulares como se querría. Hay clases que tienen más imágenes que otra e imágenes que son mucho más grandes. Inicialmente, se muestran en la siguiente tabla las 5 clases con más imágenes y las 5 con la menor cantidad.
| Clase | Cantidad | Clase | Cantidad | ||
|---|---|---|---|---|---|
| Maltes | 252 | Perro esquimal | 150 | ||
| Lebrel afgano | 239 | Affenpinscher | 150 | ||
| Lebrel escocés | 232 | Dhole | 150 | ||
| Pomerania | 219 | Pekinés | 149 | ||
| Lobero irlandés | 218 | Redbone | 148 |
Como se puede observar en esta tabla, la cantidad de imágenes entre la clase con más imagenes y la con menos, se diferencian en 100 fotos, lo que considerando los números que contienen, es una diferencia considerable, que en algún momento de análisis y entrenamiento podrían afectar. Los promedios de cantidad de imágenes en las clases y otras estadísticas se pueden encontrar a continuación.
| Estadistico | Valor |
|---|---|
| Promedio | 171.5 |
| Desviación Estandar | 23.22 |
| Moda | 150 |
| Mediana | 159.5 |
| Valor Medio | 155 |
Como se puede observar en las tablas anteriores, los valores son muy variados, aunque hay una tendencia a que las clases tengan un valor cerca a las 150 imágenes por clase. Esto implica que al momento de empezar, tanto los análisis generales como el uso del método VAE, las imágenes a usar tendrán que ser modificadas, cortando imágenes algunos lugares o agregando en otras. Otra solución posible, es limitar la cantidad de clases de análisis, usando solamente las clases que tengan una cantidad pareja de datos.
Por otro lado, se tiene que hay imágenes de diversos tamaños y proporciones. En el siguiente diagrama se pueden observar un histograma que compara la cantidad de pixeles de una imágen (se debe considerar que los valores están multiplicado por 3, debido a su componente rojo, verde y azul).
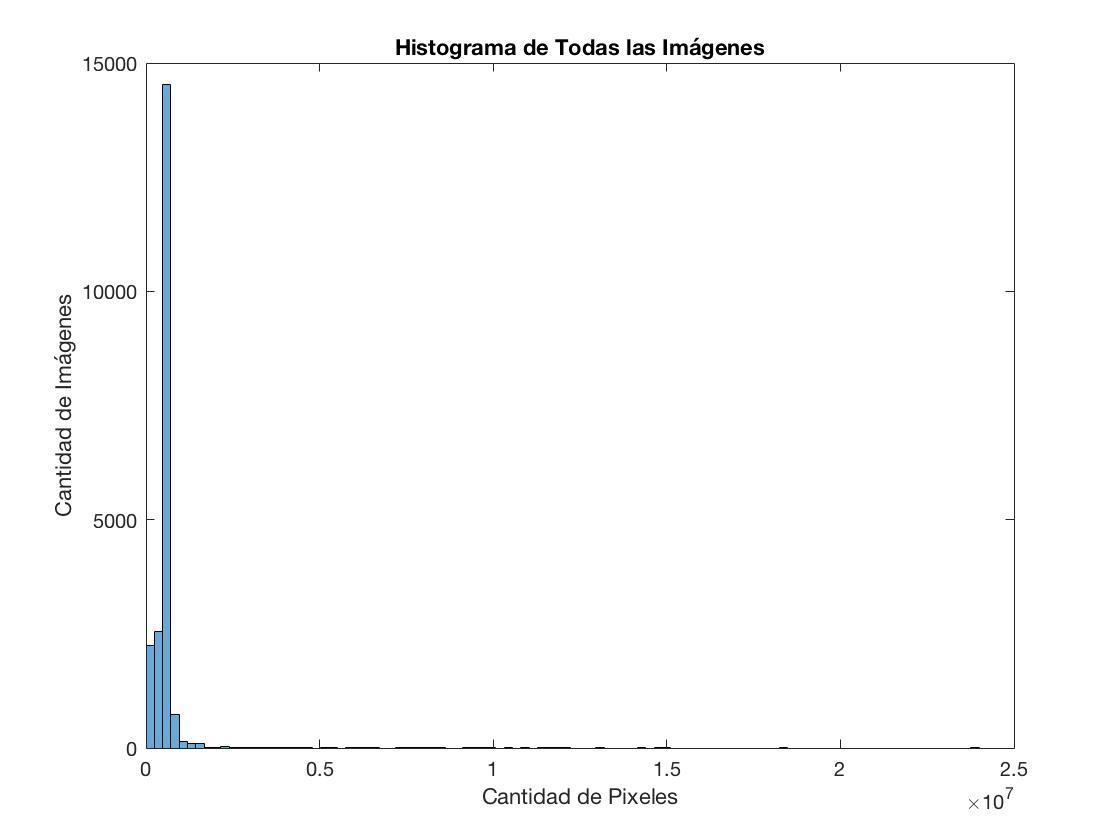
Se puede observar de este gráfico que la mayoría de los datos se encuentran en la zona inicial, en general con 600.000 datos por imágenes. pero aún así existen valores que se despegan de los datos. Por ejemplo, en las siguientes imágenes se pueden encontrar la imágen más grande y la más pequeña dentro del dataset.


Esta diferencia debe ser procesada haciendo un resize de las imagenes, así se puede asegurar que todas las imágenes tengan el mismo tamaño, y así además se pueda optimizar la cantidad de valores de entrada, que por ser una imagen, son muchas.
Por último, se puede observar que dentro de las imágenes que se encuentran en el dataset, se puede encontrar una diversidad de tipos de imágenes. Hay imágenes en las cuales se puede ver más de un perro, u otras donde no solo hay un perro, si no que lo acompaña una persona. Además, hay fotos con distintos fondos, o con los animales en distintas posiciones.

Todos estos detalles se deben tener en consiederación al momento de querer hacer el entrenamiento, sin importar el método, por lo cual es de suma importancia tener un preproceso de las imágenes previa al uso de los algoritmos a usar.
El código usado para el cálculo de todas las variables anteriores, y otros datos un poco más detallados, fueron desarrollados en la plataforma Matlab, donde se adjunta el archivo usado. Si se quiere usar, se debe poner este archivo en la carpeta donde se encuentren las imagenes de los datos y cambiar la dirección en la que se encuentra.