Similitud de Instrucciones en Código de Fuente C #.
Guillermo de la Torre - Hernán Sarmiento
Descripcion del Problema | Descripción de los Datos | Limpieza de los Datos | Exploración de Datos | Resultados | Conclusiones
Resultados
Experimentos Iniciales
Tras haber realizado el pre-procesamiento y limpieza de los datos, se efectuó el etiquetado de un set de entrenamiento inicial de 63 registros, donde se incluyó la clase Matched para representar si un par de sentencias tenía una construcción sintáctica similar o distinta con lo valores True y False, con una distribución de 29 y 34 apariciones respectivamente.
Los datos clasificados fueron utilizados en el software Weka para hacer uso de diferentes algoritmos con distintas opciones, de modo de obtener resultados preliminares del estudio. Haciendo uso de lo anterior, se elaboró un clasificador con un Árbol de Decisión utilizando J48 con Cross-validation de folds igual a 10. Lo resultados de este estudio con presentados a continuación:

Experimento inicial Árbol de Decisión J48
Como es posible apreciar, los resultados poseen un elevado valor de accuracy (cercano a 97%) así como valores muy altos para precision y recall, ya sea para la clase TRUE como FALSE. A su vez, se generó además el árbol correspondiente para exhibir el o los atributos que mejor clasifican los datos.

Árbol de Decisión J48
Este mismo experimento se repitió eliminando el atributo SmithWaterman, que según el resultado anterior era el que mejor representaba los datos previamente etiquetados. Esto se realizó para conocer si el árbol crecía en cuanto a cantidad de nodos y atributos que podían representar los pares de sentencias.

Experimento inicial Árbol de Decisión J48 sin SmithWaterman
Como era de esperar debido a la poca cantidad de datos que están siendo clasificados, los resultados no generan mayor variación respecto a los resultados estadísticos entregados previamente, los cuales pueden ser mejor reflejados al generar el árbol de decisión dado que solo presenta un atributo que puede categorizar las sentencias estudiadas.

Árbol de Decisión J48 sin atributo SmithWaterman
Experimentos finales
Debido a la falta de datos etiquetados más la poca contundencia que entregan los resultados al tener generar un árbol de tan solo 1 nivel (utilizando más de 20 atributos para aquello), se aplicaron las siguientes tareas explicadas como sigue a continuación.
Aumento de datos etiquetados
Se incrementó el número de pares de sentencias de acuerdo a si estos presentaban o no un match (True o False respectivamente). El número total de elementos considerados fue cercano a 1700 registros, de los cuales al menos 150 son de valor True para la clase Matched. Estos datos fueron escogidos de manera aleatoria y clasificados por el equipo de trabajo de manera individual, por lo cual no hay un juicio externo en la categorización de estos.
Categorización de valores en intervalos
Uno de los grandes problemas presentes en la distintas métricas consideradas, es que si bien los valores estudiados están entre [0,1], las cifras calculadas para estos atributos son continuos, lo cual dificulta en muchos casos la categorización de estos, por lo que no tener valores nominales podría negar el uso (por ejemplo) de reglas de asociación. Para solucionar este dilema, se propuso generar intervalos para cada métrica dependiendo de la distribución de los datos contenida en el estudio.
Dado que no es posible conocer el largo o la cantidad de valores que contendrá cada intervalo, se aplicaron técnicas de clustering para cada una de las métricas, calculando de esta forma la cantidad de conjuntos agrupados (clusters) que cada uno de los atributos contenía. Los métodos de clustering utilizados fueron K-Means y cluster Jerárquico de tipo complete y ward.d. Para el caso de jerárquico no se consideró la versión simple ya que no era posible apreciar de manera intuitiva la cantidad de clusters presentes a la hora de examinar el dendograma correspondiente, el cual puede ser observado tal como sigue:

Para conocer la cantidad de cluster para cada métrica utilizando K-means, se utilizó el método gráfico del “codo”. En ella, se hizo uso de la métrica para el par de sentencia sin procesar (sentencia completa, Raw) y su forma simplificada sin modificadores de visibilidad. Un ejemplo para una métrica cualquiera se presenta a continuación.

Así por ejemplo para la métrica de Levenshtein, se consideró un valor de cantidad de clusters igual a 3 y 4. Además para generar mayor cantidad de intervalos, se agregaron 2 clusters más que tuvieran un valor de 3 cifras más que el más grande encontrado en el método del codo. De esta manera, para la métrica ejemplificada, la cantidad de clusters a estudiar era de {3,4,7,10}.
En el caso de cluster jerárquico, se generó el dendograma para los métodos de complete y ward.d y en cada uno de ellos se seleccionó 2 valores de posible cantidad cluster tal como se presenta a continuación.

Elección del número de clusters para generar intervalos
Tal como se explicó antes y para el caso de k-means, se consideró una cantidad de 4 intervalos, 2 que representaban opciones distintas para el método del codo y 2 más que eran un tanto mayor que las seleccionadas con tal forma gráfica. Para cada una de estas alternativas de las métricas estudiadas, se evaluaron los resultados respecto a criterios inter e intra cluster, es decir, la suma de distancia entre los elementos del clusters y la suma de los elementos dentro del mismo cluster respectivamente (y además la suma de ambos valores) Por ejemplo, la siguiente tabla muestra los valores para una métrica y su elección de la cantidad de cluster para k-means (descargar archivo completo)
| metricsConfiguration | tot.withinss | betwenss | totss |
|---|---|---|---|
| Levenshtein_k.means.codo.A_n_3 | 62.8364 | 748.9498 | 811.7862 |
| Levenshtein_k.means.C_n_7 | 13.6486 | 798.1376 | 811.7862 |
De acuerdo a los resultados, lo que se busca en este punto es minimizar la distancia entre puntos dentro del mismo cluster y de forma contraria, maximizar la distancia entre clusters. Observando esto y tomando como ejemplo la métrica de Levenshtein, en la mayoría de los casos el mayor número de cluster por métrica era la mejor opción considerando los valores expuestos en la tabla.
Teniendo ya el número de cluster escogido, lo que se procedió a realizar fue generar las agrupaciones con los valores continuos de cada métrica de modo que estos finalmente se convirtieran en un intervalo. Dado que es posible que puedan existir “gaps” entre las distribuciones planteadas, cada intervalo fue generado considerando que el mínimo del siguiente iba a ser el máximo de anterior (descargar archivo de intervalos)
De esta forma, un valor continuo quedó finalmente descrito como uno nominal tal como se aprecia en la siguiente tabla:
| Metric | Old value | New value |
|---|---|---|
| Levenshtein | 0.8769 | (0.75, 0.9216] |
| Levenshtein | 0.5238 | (0.4815, 0.5962] |
Re-elección del número de clusters para generar intervalos
Según lo mencionado anteriormente, los mejores resultados de la cantidad de cluster de cada métrica se reflejó en los que poseían la mayor cantidad de grupos generados (intervalos). Para examinar el efecto de estos resultados, se tomaron los datos ya categorizados y se aplicó un clasificador de árbol de decisión J48 sobre ellos para conocer el comportamiento de esta solución. Al analizar el árbol resultante, se apreció una mala distribución de los datos debido a la excesiva cantidad de intervalos, lo cual en la mayoría de los casos generaba nodos que no contenían valores, produciendo así una estructura de gran altura y con poca distribución homogénea de los datos (ver árbol completo). Además, se aplicaron reglas de asociación las cuales tampoco generaban buenos resultados. Por un lado, los tiempos de ejecución eran excesivos (y en algunos casos incuantificables) debido a la gran cantidad de reglas resultantes y en otros donde inclusive no generaban resultados.
Dada la situación anteriormente descrita, se procedió finalmente con la elección de uno de los 2 posibles valores que estaban precisamente en el codo del método gráfico descrito anteriormente, por lo cual se volvieron a generar los intervalos utilizando un nuevo valor de cantidad de clusters para cada una de las métricas (descargar nuevo archivo de intervalos)
Reducción de atributos
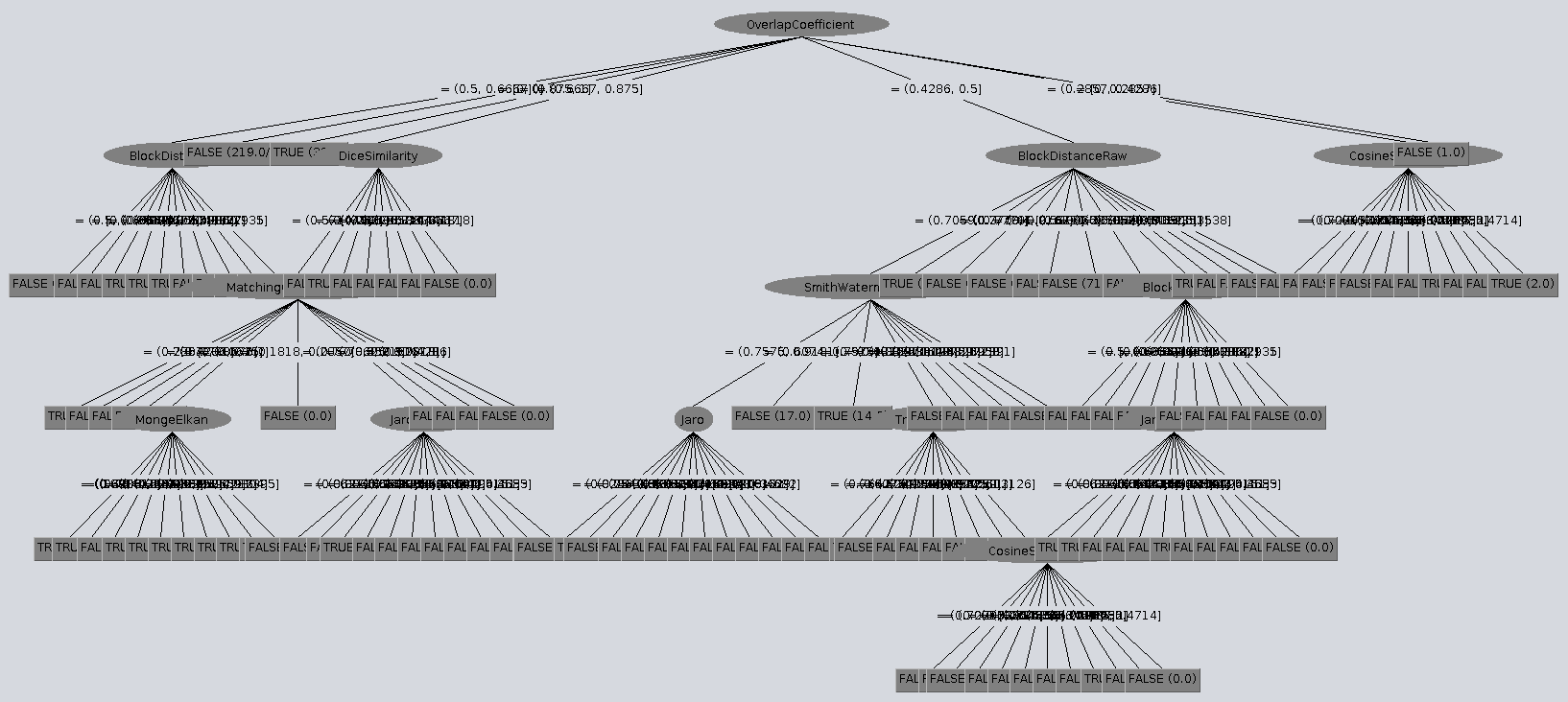
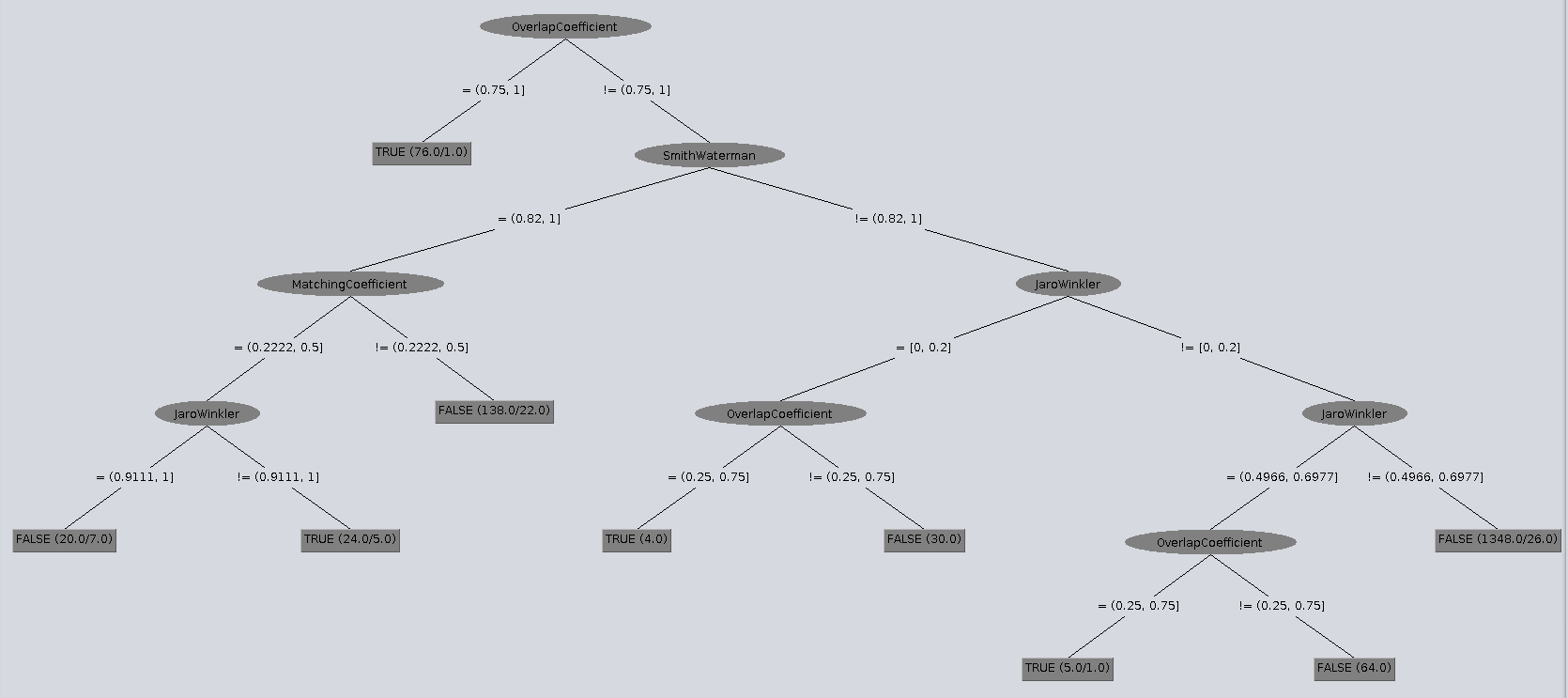
Nuevamente se repitió el experimento de generar un árbol de decisión pero ahora con los nuevos intervalos generados por el método del codo. En esta ocasión, el tamaño del árbol así como la distribución de valores en cada uno de los nodos es mucho más clara, reduciendo excesivamente elementos innecesarios en él. Esto se puede aprecira en la imagen tal como sigue
 (
({kind=link}
{kind=link}
Sin embargo, aún la cantidad de elementos del árbol parece ser excesiva, dado que en la práctica para evaluar solo un par de sentencias, sería demasiado costoso evaluar cada una de estas con las métricas presentadas en el árbol, por lo que la reducción de atributos es necesaria en este sentido.
Para lograr la reducción en la cantidad de atributos, los pasos a seguir fueron los siguientes:
- Por cada métrica, conocer el número de aciertos para la clase Matched, la cual representa si 2 pares de sentencias tienen el mismo significado sintáctico con valores True y False.
- Calcular los valores de Recall, Precision y Accuracy
- Ordenar las métricas y sus respectivos intervalos de acuerdo al Accuracy calculado.
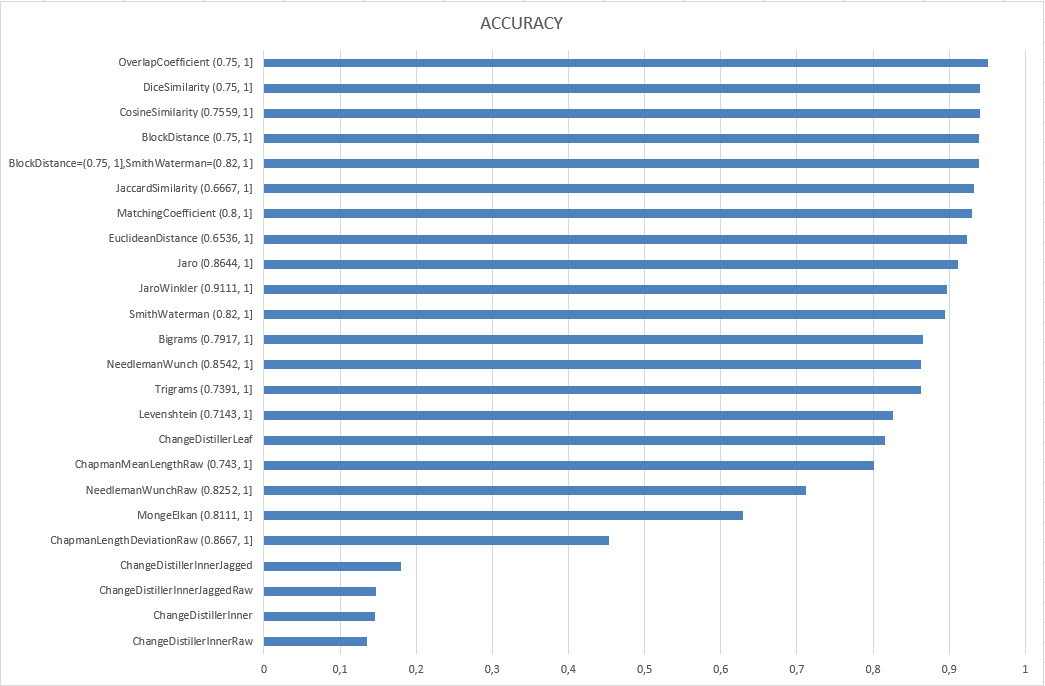
Según la finalidad de nuestro trabajo de investigación, uno de los resultados esperados es que se genere la mayor cantidad de True Positive y True Negative, es decir, que se clasifiquen de manera correcta los valores de True y False de la clase Matched. Es por esto que el principal indicador a tener en cuenta es el Accuracy, obteniendo los resultados resumidos en el siguiente gráfico (ver archivo completo con resultados)
 (ver imagen en tamaño completo)
(ver imagen en tamaño completo)
{kind=link}
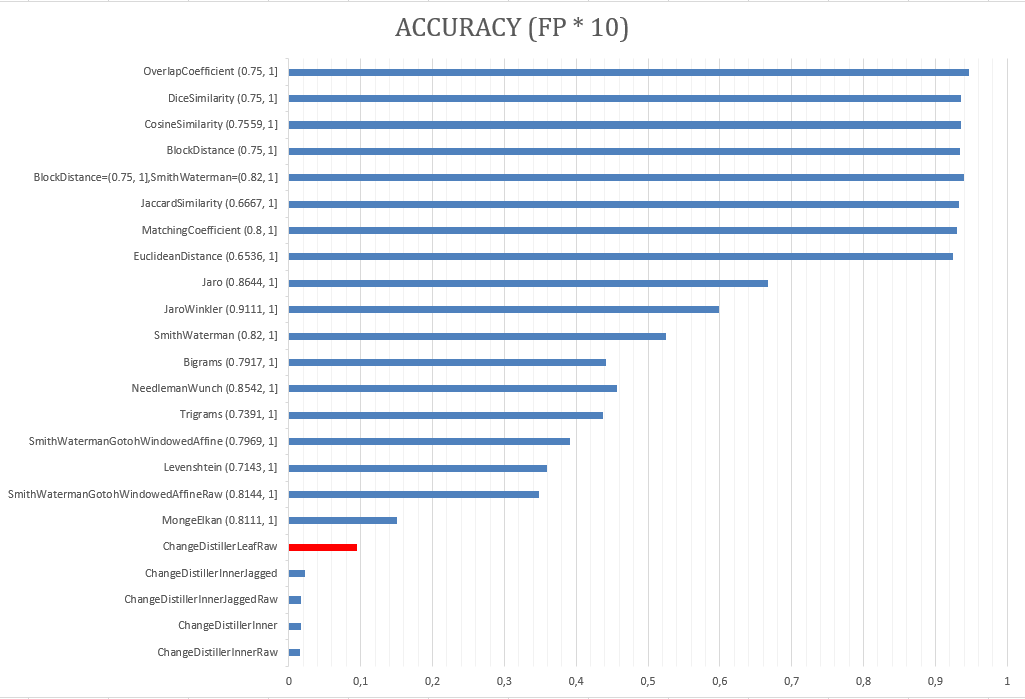
Además de considerar el valor de Accuracy, también se realizó una penalización a los False Positive para tras ello, calcular nuevamente el indicador mencionado de forma que el valor fuera más preciso acorde a la realidad del problema.
 (ver imagen en tamaño completo)
(ver imagen en tamaño completo)
{kind=link}
Finalmente con los cálculos y penalización explicados, se realizaron los siguientes pasos:
- Se analizaron las métricas en su versión completa (raw) y simplificada. En general, la versión simplificada tenía mejores valores por lo que se optó por utilizar aquellas.
- Se escogieron las métricas que poseían sobre un 50% de Accuracy con penalización.
De esta forma, la cantidad total de atributos se redujo a 10 métricas a evaluar en el árbol de decisión así como en reglas de asociacion.
Reglas de Asociación
Ya con los atributos reducidos y seleccionados, se aplicaron reglas de asociación de modo de generar item que estén estrechamente asociados en el set de datos estudiado. Esta relación básicamente se calcula buscando en el lado derecho de la relación (rhs) si el valor True está presente. En primer término, se buscaron las reglas en el cual el largo lado izquierdo (lhs) fuera de largo 1 para así solamente estudiar las reglas para una métrica de manera individual. Alguno de los resultados ordenados por lift fueron los siguientes:

De estos resultados es preciso observar que las métricas que poseen mayor lift son justamente las que mejores resultados de accuracy con penalización fueron obtenidas del proceso anterior, lo cual puede insinuar de primera instancia que podrían ser buenos discriminadores para rechazar o aceptar un match entre pares de sentencias.
Adicionalmente, se aumentó el tamaño del lado izquierdo del item set para tener en esta ocasión 2 elementos en el ya mencionado. Los resultados generados son presentados a continuación:

En general y para ambos casos, el valor de support es bastante bajo (cercano a 3% del total de transacciones) esto debido a la poca cantidad de clases Matched con valor True existentes en todo el dataset. Por aquella razón las observaciones se centraron en el lift para encontrar un alto grado de dependencia entre ambos lados del set analizado.
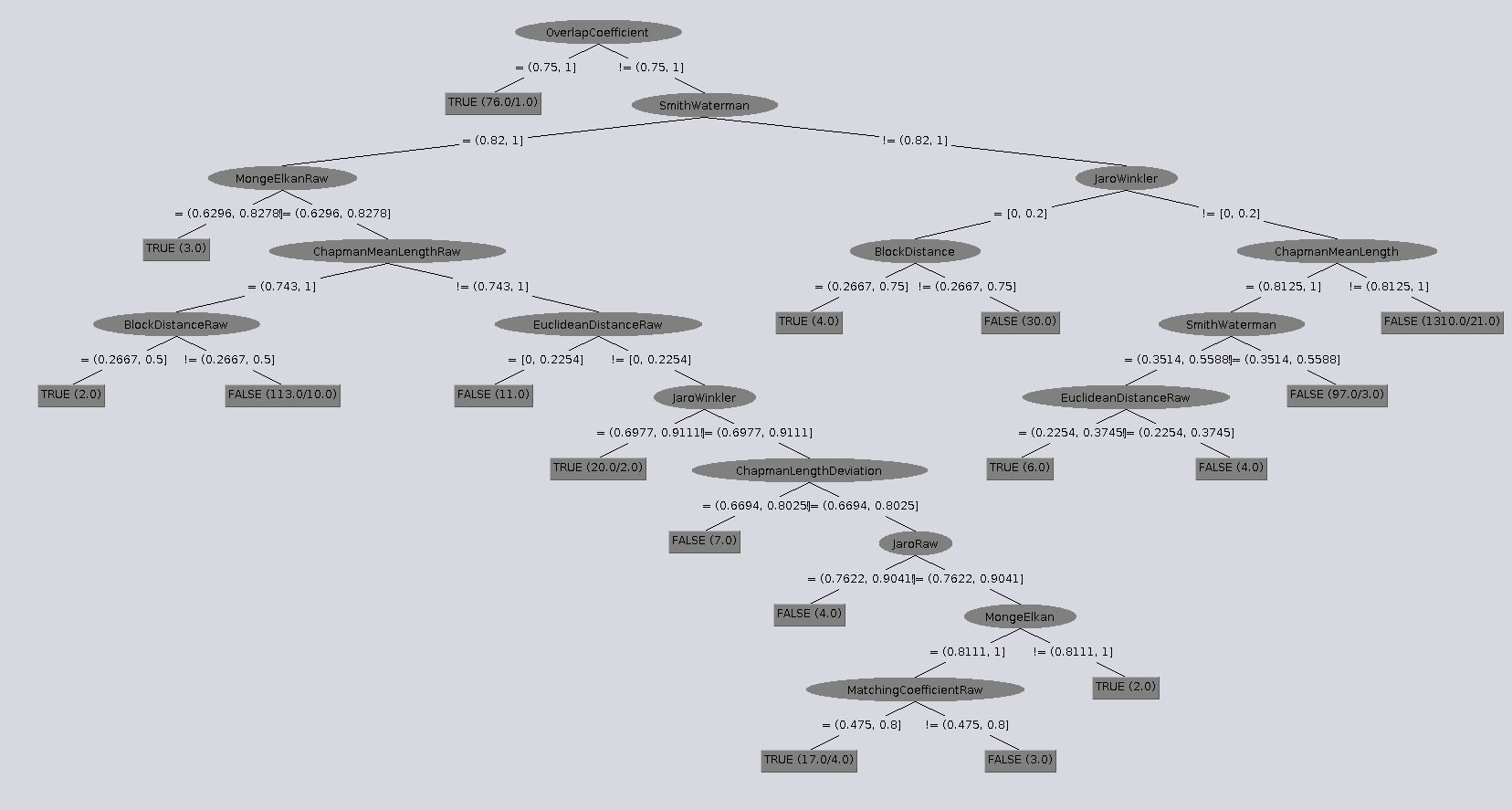
Clasificación
Utilizando los mismos atributos anteriores, también se creó un clasificador con un árbol de decisión J48 de modo de crear un método que pueda distinguir de mejor manera una sentencia que presenta match pero con un costo más alto al poseer una mayor cantidad de métricas y evaluaciones que en la práctica podrían ser más costosas. Los resultados y el árbol generado en esta experiencia son expuestos a continuación:

 (ver árbol en tamaño completo)
(ver árbol en tamaño completo)
{kind=link}
Observando los resultados, estos presentan una buena cantidad de instancias correctamente clasificadas así como un buen Precision para la clase True y False. Sin embargo el Recall de la primera clase nombrada es bastante bajo, lo cual podría ser explicado por la poca cantidad de True presentes en el dataset que tiende a mermar el clasificador hacia valores más falsos.