Descripción de los datos
Los datos utilizados se obtienen de dos fuentes principales. En primer lugar, se utiliza The Movie Dataset publicada en kaggle.com, que contiene infromación sobre más de 45.000 películas. Esta base de datos incluye, además de atributos básicos tales como título, fecha de estreno, país de origen, género y duración de cada película, los siguientes campos principales:- Presupuesto.
- Recaudación.
- Palabras Claves.
- Descripción.
- Elenco.
- Realizadores.
- ID de la película en imdb.com..
Además de lo anterior, se decide utilizar el campo correspondiente a la ID en imdb.com para extraer información adicional desde este sitio, de modo de complementar los datos disponibles en The Movie Dataset. En concreto, se implementan rutinas para descargar y procesar dos tipos de datos desde IMDb:
1.Información de premios: datos de todos los premios a los que la película haya sido nominada, incluyendo nombre de la ceremonia, año, categoría del premio, a quién va dirigido en concreto, y resultado (ganador o nominado).
2.Información de valoración de usuarios: detalle de número de votos y valoración promedio, dividido por sexo y rango etáreo de los usuarios (<18, 18-29, 30-44 y 45+), y por número de votos por nota (en escala de 1 a 10). El código completo utilizado para esta parte puede ser revisado aquí
Exploración Inicial
Como paso previo a la exploración, se realiza un filtrado preliminar en Python de ambas bases de datos utilizadas. En concreto, se crea una versión reducida de los datos de premios, que incluye tan solo una entrada por cada combinación de película y ceremonia, en la que se indica el número total de premios ganados y nominaciones, y que se guarda en el archivo ‘awards_condensed.csv’, mientras que la versión completa de los datos (con una entrada para cada premio al que fue nominada cada película, incluyendo categoría y detalles adicionales) se exporta como ‘extra_awards.csv’. Se crean además otros dos archivos, ‘country_freq.csv’ y ‘keyword_freq.csv’, que incluyen un resumen global de frecuencias absolutas para los datos de país de origen y palabras clave, respectivamente, en la base de datos (esto para facilitar el análisis en R, dado que ambos campos pueden presentar múltiples valores por película, y se presentan originalmente como listas de diccionarios con los nombres de las variables y códigos que las representan). Finalmente, se realiza un pequeño filtrado de la base de datos de The Movie Dataset, en el que se conservan sólo aquellas películas para las que se pudo obtener información de valoración y premio, se eliminan algunos campos que no se pretende utilizar (‘poster_path’ y ‘homepage’), se actualizan los campos de ‘vote_average’ y ‘vote_count’ para que sean consistentes con los datos extraídos desde IMDb, y se computan métricas adicionales que tienen por objetivo caracterizar la respuesta de la audiencia más allá del promedio o el número de votos. En particular, se incluye la desviación estándar de los votos, como una métrica de que tan “polémica” es una determinada película, así como la desviación estándar por edad y por sexo, de modo de caracterizar películas que generan divisiones en estos sentidos. Todo lo anterior se exporta en el archivo ‘filtered_movie_data.csv’. El código completo correspondiente a este filtrado preliminar se puede revisar aqui .El resto de la exploración se lleva a cabo en R, para lo que se comienza cargando los archivos descritos anteriormente como sigue: awards <- read.csv("./databases/extra_info/extra_awards.csv", header=TRUE)
awards_condensed <- read.csv("./databases/extra_info/awards_condensed.csv", header=TRUE)
movie_data <- read.csv("./databases/extra_info/filtered_movie_data.csv", header=TRUE)
country_freq <- read.csv("./databases/extra_info/country_frequencies.csv", header=TRUE)
keyword_freq <- read.csv("./databases/extra_info/keyword_frequencies.csv", header=TRUE)
De esta manera, y utilizando las funcionalidades de navegación de RStudio, es posible obtener algunas informaciones iniciales acerca de los datos utilizados: se cuenta con información para un total de 45.264 películas, de 161 países de origen distintos y etiquetadas con 19.917 palabras clave diferentes, así como de 255.010 nominaciones y premios entregados. Usando la función ‘unique’:
ceremonies <- unique(awards_condensed$ceremony)
se obtiene además que estos datos incluyen información para 2.388 instancias de premiación diferentes. Para visualizar la distribución de películas por año dentro de la base de datos, se genera el histograma correspondiente de la siguiente forma:
hist(movie_data$release_year, breaks=145, xlab="Año", ylab="Cantidad de películas", main="Total de películas por año")
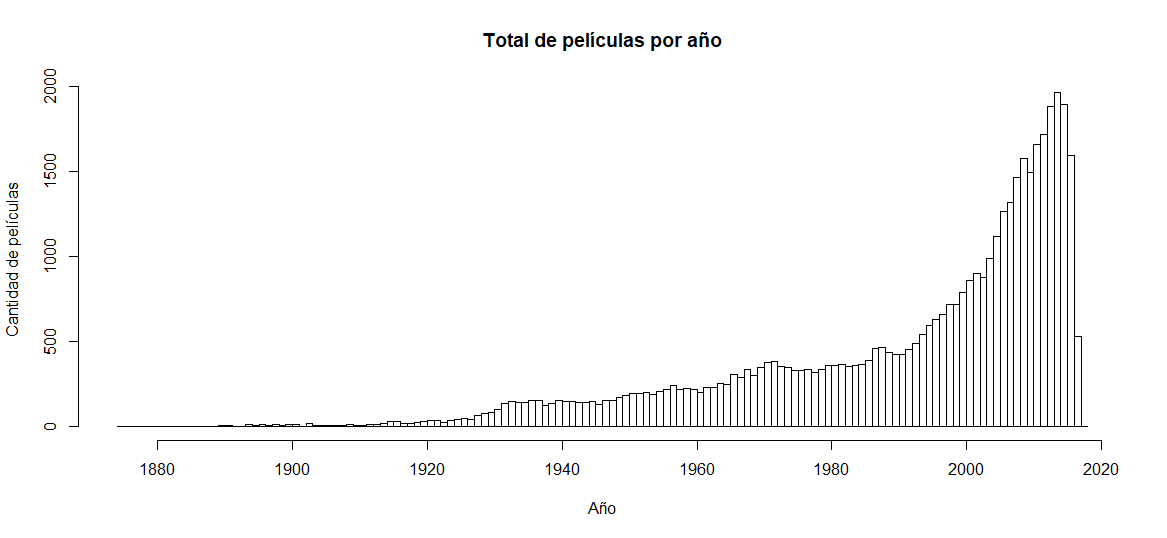
observándose películas de todas las épocas, a partir de finales del siglo XIX, pero con una clara concentración hacia las últimas 5 décadas. Se utiliza además la información calculada sobre frecuencias absolutas de países de origen y palabras clave para graficar los histogramas correspondientes, de la siguiente manera:
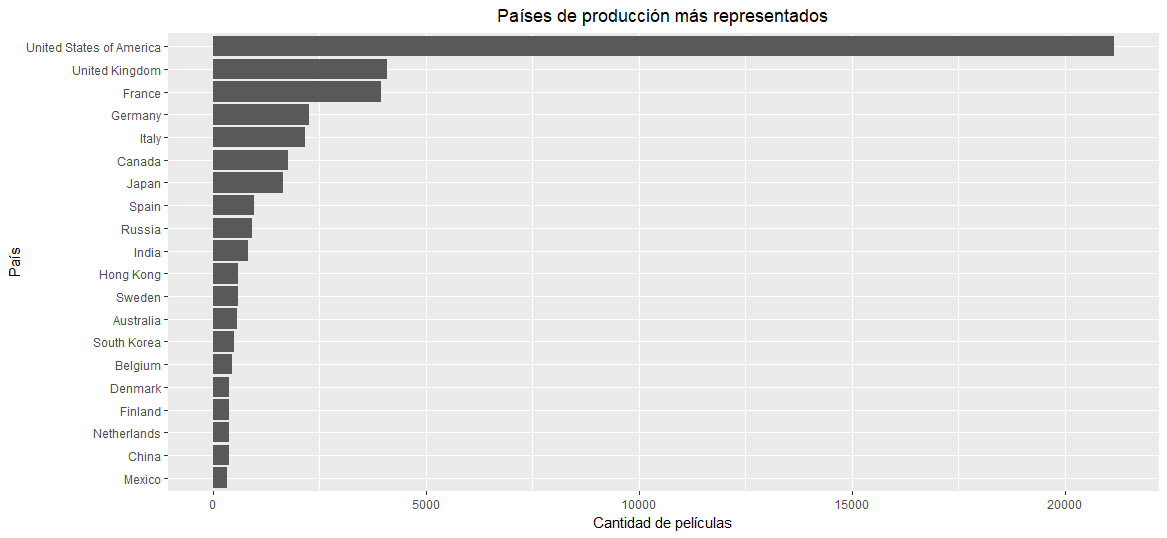
ggplot(head(country_freq[order(country_freq$count, decreasing=T),], 15), aes(x=reorder(country_name, count), y=count)) + geom_bar(stat="identity") + coord_flip() + ggtitle("Países de producción más representados") + theme(plot.title = element_text(hjust = 0.5)) + xlab("País") + ylab("Cantidad de películas")
ggplot(head(keyword_freq[order(keyword_freq$count, decreasing=T),], 25), aes(x=reorder(keyword, count), y=count)) + geom_bar(stat="identity") + coord_flip() + ggtitle("Palabras clave más frecuentes") + theme(plot.title = element_text(hjust = 0.5)) + xlab("Keyword") + ylab("Frecuencia")
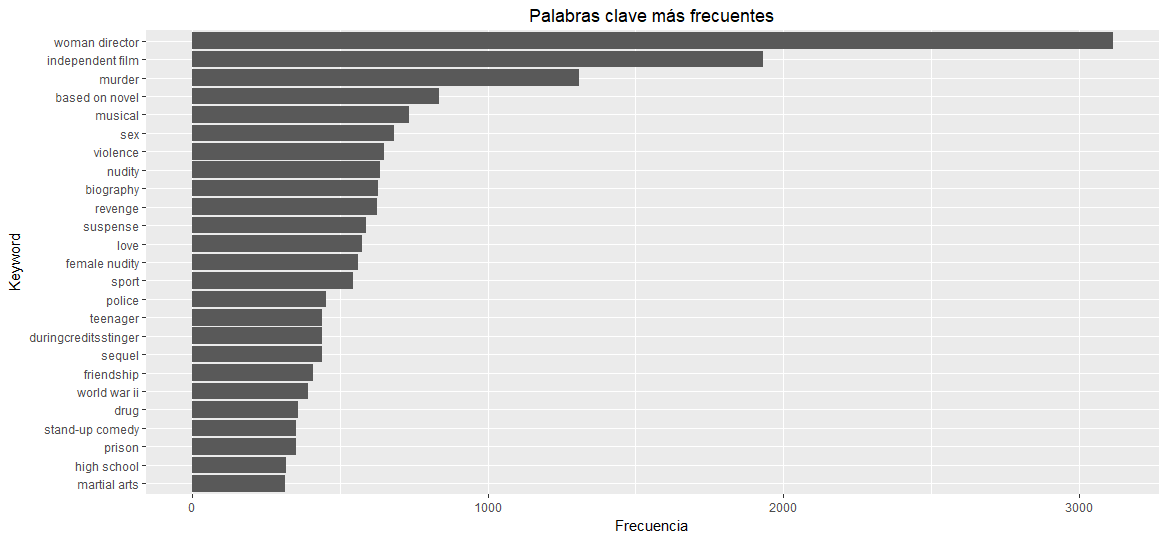
De acuerdo a lo anterior, se observa una clara dominación de EE.UU. y países europeos en la base de datos, así como gran variedad de palabras clave, que incluyen tanto conceptos temáticos de la trama (tales como ‘asesinato’ o ‘amor’), como metadatos de la película (como ‘director mujer’, ‘secuela’, o ‘basado en una novela’’). Análogamente, se calculan las frecuencias absolutas de aparición de las distintas ceremonias de premiación, y se grafica su histograma como sigue:
ceremony_freq <- data.frame(table(awards_condensed$ceremony)) ggplot(head(ceremony_freq[order(ceremony_freq$Freq, decreasing=T),], 20), aes(x=reorder(Var1, Freq), y=Freq)) + geom_bar(stat="identity") + coord_flip() + ggtitle("Ceremonias de premiación más representadas") + theme(plot.title = element_text(hjust = 0.5)) + xlab("Ceremonia") + ylab("Cantidad de películas con participación en la ceremonia")
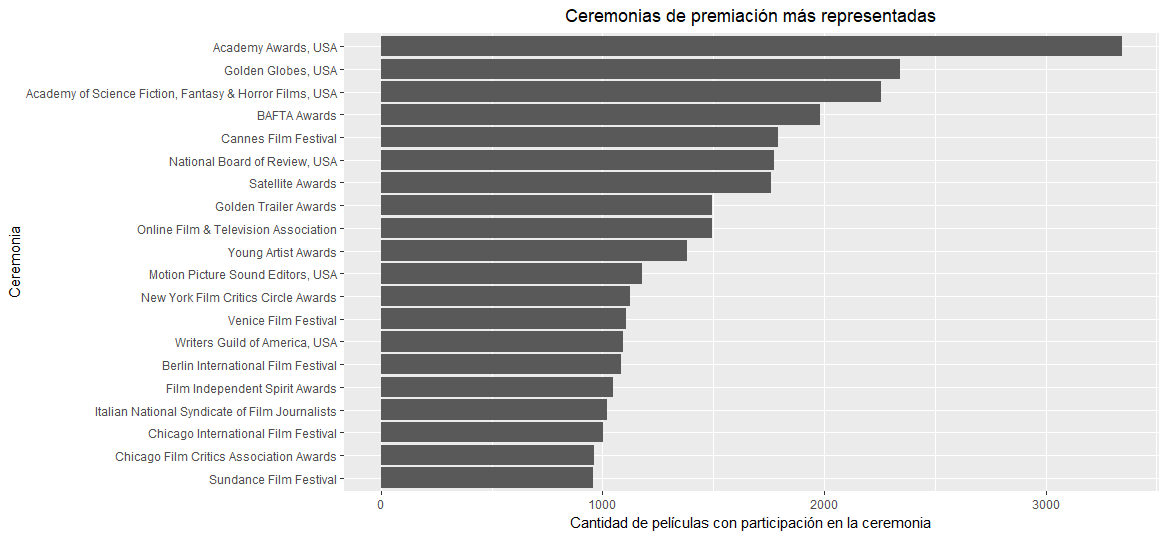
Observándose una gran cantidad de películas con al menos una nominación a los Oscar (3.327 películas), lo que resulta importante para el problema abordado, así como gran representación para otros festivales y ceremonias de EE.UU., que podrían servir como indicadores potentes para predecir los resultados de los premios de la Academia. De la siguiente forma se filtran sólo aquellas películas con al menos una nominación a los Oscar:
oscars <- awards_condensed[awards_condensed$ceremony=="Academy Awards, USA", ]
nominated_movies <- unique(oscars$imdbId)
movie_data_oscars <- subset(movie_data, imdbId %in% nominated_movies)
Sobre la selección anterior, se filtran además sólo aquellas películas con al menos 100.000 votos, y se ordenan según la desviación estándar de los votos, para realizar una evaluación preliminar de la eficacia de este indicador para medir qué tan polarizada es la recepción de una película:
movie_data_popular <- movie_data_oscars[movie_data_oscars$vote_count>100000, ] head(movie_data_popular[order(movie_data_popular$vote_std, decreasing=T), c("title", "release_year", "vote_average", "vote_std")], 5)

Con lo que los resultados obtenidos parecerían indicar que la desviación estándar es un buen índice para medir lo que intuitivamente entenderíamos como una película que polariza a la audiencia.