Hito 3
Se realiza una recopilación del trabajo hecho durante el semestre, además del avance hecho para finalizar el trabajo, junto con los resultados obtenidos.
Introducción
La forma en que nos relacionamos con nuestras mascotas se encuentra en constante cambio, es cada vez más importante mantener su salud física y mental en altos estándares, productos y servicios especializados para este objetivo abundan y no dejan de multiplicarse. La necesidad por clínicas veterinarias, accesorios para mascotas y hasta seguros de animales, no dejan de crecer; American Pet Products Association verifica esto publicando que el mercado de mascotas ya casi alcanza los 70 billones de dólares. Existen incluso redes sociales de dueños de mascotas, dedicados a compartir información sobre cuidado general de la mascota, un ejemplo popular es el sitio hispano FacePets.
Con un mercado en crecimiento, resulta natural que los productos y servicios se empiecen a especializar, cubriendo necesidades de condiciones o razas acotadas, tales como shampoo para pelo de cierta forma o color, o cuidados especiales para prevenir enfermedades frecuentes en ciertas razas o especies. Detectar estas necesidades traería un beneficio considerable a prácticamente cualquier miembro de la industria, sin embargo, hacerlo de forma precisa constituye un gran desafío.
Para abordar esta problemática, podemos aprovechar la existencia de redes sociales dedicadas a animales, pudiendo extenderlo a redes sociales regulares donde sabemos que la gente comparta cierta información sobre sus mascotas. En estos sitios se comparten fotos y en algunos casos información general de la mascota.
Objetivo
El desafío consiste entonces en, a partir de muy poca información, un conjunto de características relevantes de la mascota del usuario para encontrar una necesidad por cierto producto o servicio, el equipo cree que las fotografías son, en muchos casos, suficiente para poder encontrar algunas características accionables, y se centrará en particular en perros.
Un experto en perros podría nombrar la raza del animal con tan solo una fotografía, pero, como se busca dar solución a un problema muy grande, se requiere cierta automatización del proceso. Se recurre entonces a herramientas de minería de datos para agrupar usuarios según las necesidades de sus mascotas y permitir la gestión de anuncios y ofertas personalizados, tal cual lo hace Netflix o Google para mejorar sus sugerencias.
Teniendo en mente que el estudio de imágenes no es tarea sencilla, el equipo trabajará con aprendizaje no supervisado, evaluando el desempeño de algoritmos de clustering con diversos tratamientos previos a un conjunto de imágenes.
Los datos
Las imágenes utilizadas en el estudio corresponden a un dataset de la Universidad de Stanford con fotografías de 20.580 perros de 120 razas diferentes. El dataset en sí es muy heterogéneo, pues tiene fotografías de diversos tamaños, con distintos tipos de iluminación, más de un objetivo en la escena y con objetivos poco distinguibles respecto al fondo, volviendo necesaria una estandarización previa.
Las fotografías se recortaron y escalaron, transformándolas en fotos cuadradas con 140 pixeles por lado. Como este tratamiento requiere la identificación del objetivo en la imagen, es difícil de automatizar y se realizó con un subconjunto del dataset original seleccionado aleatoriamente.

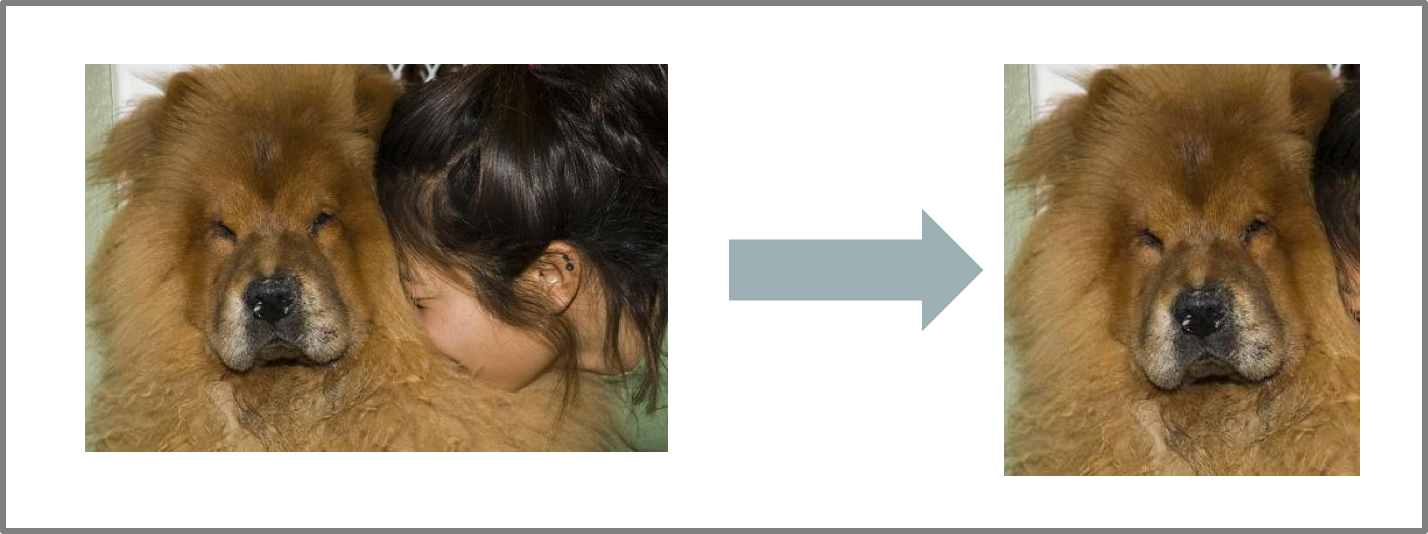

Aunque los datos tienen etiquetas con las razas de cada perro, no se utilizará tal información, pues se busca extraer características desde las imágenes sin ningún dato adicional, de cualquier modo es razonable que una misma raza esté dividida en distintas clases, por ejemplo, por distintos colores de pelo.
Trabajo Anterior
Como inicio del trabajo, para empezar a introducirse en el problema y en el proyecto, se realizaron dos trabajos inicialmente durante le hito 2.
Uno de ellos, ya comentado durante la sección anterior, fue el preprocesamiento y entendimiento de los datos. Para ello, se realizó el proceso anterior de recorte y de resize de las imagenes, además de analizar ciertas razas y tipos de perro a través de histogramas, ya que los colores de los pixeles son el único dato que se dispone para el análisis de las imagenes, además de las razas, lo cual no fue considerado. Para más detalles.
Por otro lado, se realizaron dos entrenamientos, uno con K-means y el otro con clustering aglomerativo, usando todos los pixeles que componian la imagen. Para esto se usaron solo tres razas aleatorias, las cuales obtuvieron un accuracy de 46,2% para el caso de k-means, y para el caso de agglomerative clustering de 41,4%, 38,5% y 41%, usando 3 formas, ward, average y complete, respectivamente.
Para más detalles, se puede observar el trabajo realizado durante el hito 2, link en la parte inferior de la página.
Disminución de datos y extracción de características
Con el propósito de cumplir el objetivo de nuestro proyecto se siguió con las mismas ideas de reducir la dimensionalidad de los datos para que en este espacio de menor dimensionalidad la clusterización pudiera ser más sencilla.
El objetivo de reducción de dimensionalidad es que en este nuevo espacio más pequeño se encuentran las características más relevantes de los datos. Uno de los principales algoritmos que ocupamos para este proceso fue PCA, el cual puede ser revertible, es decir PCA tiene una transformación inversa que permite obtener los datos en el espacio original.
Como sea para poder realizar clusterización no es necesario utilizar un algoritmo que sea revertible, se puede ocupar entonces un algoritmo preentrenado que sólo codifique. Esto podría ser por ejemplo una red neuronal preenetrenada, se deja para trabajo futuro este tipo de tarea la cual tiene características positivas en el sentido que tener una red preentrenada puede obtener características más relevantes que un aproach no supervisado como el que realizamos en este proyecto.
Cabe decir que inicialmente el proyecto presentado quería encontrar los clusters de perros, es decir mediante un proceso de clusterización encontrar la clase de cada perro, pero observándolo desde un punto de vista económico y de datos se optó por la búsqueda de características relevantes que pueden servir para sistemas recomendadores. En general este proyecto se puede advertir como una fase de preprocesamiento más elevorada que una usual, aunque al mismo tiempo la metodología que siguió en este proyecto cabe dentro del framework de minería de datos.
Experimentos
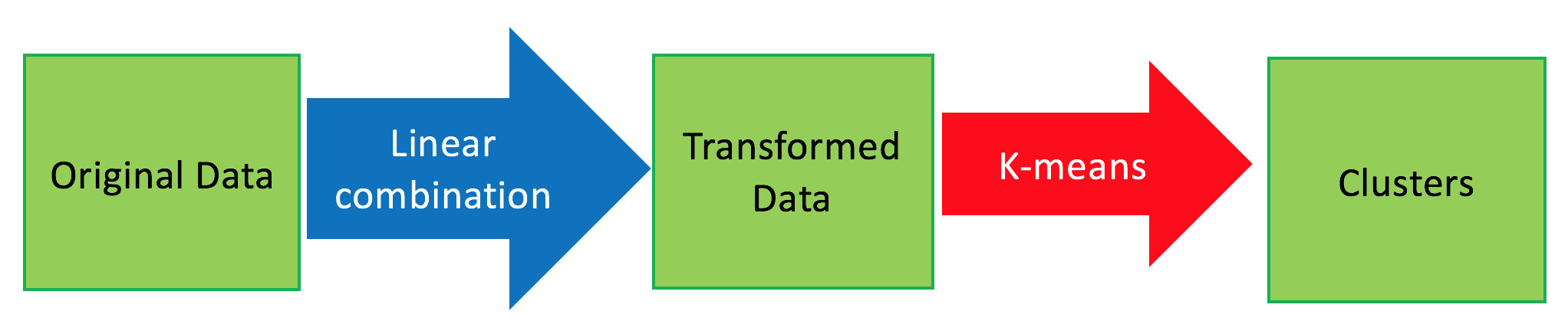
El primer algoritmo que se utilizó fue PCA, para la reducción de dimensionalidad como se había comentado. Esquemáticamente corresponde a un aproach observado en la siguiente figura.

Algunas consideraciones prácticas son necesarias para obtener características relevantes utilizando la transformación de PCA y es que:
- Las características tienen que ser representativas y poder explicar los datos de manera adecuada. En general es difícil testear este comportamiento, lo que se realizó entonces fue corroborar que la transformación de PCA inversa pudiera reconstruir adecuadamente las imágenes.
- El número de componentes principales elegidas debe ser el menor número posible.
El punto 1 y 2 se deben cumplir, finalmente se eligió iterativamente el menor número de componentes posibles que a la vez pudiera reconstruir las imágenes.
A continuación se muestran las imágenes originales y reconstruidas.


Se intentaron 2 dataset uno con 3 clases de perros y otro con 20. Se encontró que se necesitan 500 y 5000 dimensiones respectivamente para estos datasets.
Para realizar K-means: Se utilizaron 3, 10 y 30 clusters. Para 10 y 30 clusters se encontraron agrupaciones de características más interesantes.
El framework utilizado es como se muestra a continuación.
Los clusters encontraron son principalmente contextuales teniendo mucha importancia el color. A continuación se muestran algunos clusters interesantes encontrados.
Cluster de perros al aire libre

Perros claros

Perros oscuros

Con los resultados anteriores se encuentran espacios o características al menos para poder recomendar por ejemplo productos en base al pelaje o por ejemplo si está en muchas áreas verdes juguetes o artículos deportivos.
Todos los experimentos anteriores también se realizaron para las imágenes realizándoles un resize a una imagen de 34x34, el objetivo de este procedimiento es que se tenía la intuición es que los detalles desaparecían hacer el resize y esto tenía como consecuencia que el algoritmo se fijara aún más en el contexto, aun así los resultados no fueron mayormente distintos. Un ejemplo de perros claros se muestra a continuación.

Cabe decir que todos los resultados se pueden encontrar en los jupyter notebooks adjuntos, donde se encuentran de forma transparente los resultados.
El framework presentado hasta ahora abarca una solución a un problema que está muy relacionado a los colores de las imágenes, también sería interesante obtener características utilizando algoritmos que tuvieran en cuenta la forma. En particular se utilizará HOG (Histogram oriented gradient) que en los años 2000 tuvo éxito funcionando como detector de objetos combinándolos con otros métodos. Notar que la metodología es la misma, HOG funcionará como un codificador y se intentará clusterizar con K-means.
Lamentablemente los resultados no fueron exitosos. La variabilidad de las imágenes era muy alta detectando variados bordes y por lo tanto formas que no se podían interpretar de manera sencilla. Un cluster usando HOG se muestra en las imágenes se presenta a continuación, este es uno de los pocos cluster interesantes y aun así no es fácilmente interpretable, este cluster corresponde a imágenes donde el contexto o ambiente no tiene grandes variaciones y por lo tanto el perro que en general tiene varios es detectable.


Algo que podría haberse realizado para extender o estudiar más en profundid HOG es realizar HOG por canales de imágenes y no por la imagen en grayscale como se hiso.
Una de las conclusiones más relevantes que observamos en este proyecto es advertir los límites que tienen los algoritmos y lo que pueden conseguir estos para ciertas tareas. En este caso se realizó una tarea de alta dificultad que consistía en conseguir características relevantes en imágenes de alta definición que entre clases eran altamente variables y además cada imagen al mismo tiempo podía tener una gran cantidad de objetos o outliers que dificultaban o agregaban ruido al problema.
De los algoritmos presentados se concluye que estos pudieron obtener características generales, principalmente color y contexto de cada imagen. Aunque se intentaron algoritmos basados en formas de la imagen o gradientes de esta (HOG) no se obtuvieron resultados, esto principalmente por las formas altamente variables que se pueden encontrar una imagen. Una posible solución es utilizar modelos que son exitosos en estas tareas, como redes neuronales convolucionales de forma supervisada utilizando una red preentrenada, así utilizar las características aprendidas por esta red para realizar la clusterización. Notar que en el proyecto si se intentó utilizar redes neuronales convolucionales pero de forma no supervisada, está es una tarea más dificultosa y a esto se le atribuye la obtención de buenos resultados utilizando esta metodología, en códigos anexos se pueden observar las implementaciones en Tensorflow de estos algoritmos.
Los codigos se pueden obtener apretando acá.
Análisis de una Característica
A continuación, para poder centrar mejor los resultados y el análisis hecho, se procede a buscar el análisis de solo una de las características observables de las fotos y los animales, al cual es el color del pelaje. La idea es poder detectar el color del pelaje del perro, o por lo menos la tonalidad, y asi, según el color encontrado, poder ofrecer, por ejemplo, productos de cuidado de pelaje exclusivo para el animal en cuestion.
Analizando el trabajo realizado con anterioridad, se puede observar que, aunque los resutados de análisis no arrojaron buenos resultados, la cantidad de pixeles de cierto color puede influir en el análisis, para poder así diferenciar distintos pelajes, por lo cual, el uso del valor de los pixeles de las imágenes serán los datos utilizados para obtener los cluster requeridos.
Como segundo detalle, y para obviar el problema del hito anterior, en vez de usar todos los pixeles que componen la imágen, que sesga a que la imagen tenga la misma distribución de los colores en ella, además de agregrar mucha dimensionalidad al problema, se usan los histogramas de la la cantidad de colores que se tienen en la imagen. De esta forma, cada color (R-G-B) tiene 15 columnas, las cuales tienen la distribución de la cantidad de pixeles de cierto color, o sea, en total una cantidad de 45 dimensiones de datos.
Finalmente, para aumentar los datos y obviar ciertas combinaciones de colores, además de trabajar en imagenes a color (R-G-B), se hace la transformación de estas imágenes a rango blanco-negro, lo que da un total de 15 columnas con la distribución de estos valores, o que equivale a la misma cantidad de dimensiones.
De esta forma, para el desarrollo de esta sección, se usa esta transformación de los datos para realizar los entraniemtos. Cabe destacar que para este proceso se utilizará K-means como método de entrenamiento, ya que gracias a la facilidad de encontrar outliers con Agglomerative Clustering, es muy facil no encontrar los cluster que se están buscando
Otro detalle importante es el hecho de que para este entrenamieto se entregan tres razas de perro, las cuales tienen colores blancos, cafes y negros, los cuales no necesariamente son de la misma raza. Con esto, se usa como parámetro de k-means un total de 3 cluster, para encontrar lo que ya sabes que ocurre.
Clusters identificados con histogramas RGB



Clusters identificados con histogramas blanco y negro



Se puede observar de estos resultados que el fondo de la imagen influye mucho en el resultado, obtiendo imagenes que son muy oscuras en un lugar sin importar el perro, otras que son muy claras sin importar el perro, y otras que tienen ambos matices, las cuales son una mezcla entre lo que ocurre en el fondo y lo que ocurre en la primera plana de la foto, entregando perros blancos con fondo oscuro, o perro oscuro con fondo blanco.
Observando lo anterior, se realiza a continuación una afirmación muy fuerte y que, aunque es muy cesgada, puede dar buenos resultados en una gran cantidad de fotos al implementarlo. Se sustenta la afirmación de que el perro si o si, sin importar la imagen se encuentra siempre en el centro de la imagen. Esto implica en el desarrollo, que además de la implementación de resize hecha ya en el preprocesamiento de datos, se procede a recortar la imagen para dejar solo el centro de esta. Aunque se realizaron en total 3 tipos de rectorte (100x100, 80x80, 60x60), solo se muestran a continuación solo los cluster con el mayor recorte (60x60).
Clusters identificados con histogramas RGB con imagen recortada



Clusters identificados con histogramas blanco y negro con imagen recortada



Se puede observar de lo anterior que mejoran los resulados, dejando de lado problemas como el grupo con mucho contraste entre el perro y el fondo de la imagen. Se pueden ahora rescatar mejores resultados solo del color del perro, pero aun asi hay casos en los cuales la clasificación, producto del recorte no funcinan, como la imagen de los dos perros en el primer grupo del trabajo en RGB. Cabe destacar que en este trabajo se repitió constantemente el caso del perro que se puede observar en el segundo grupo del blanco y negro, en el cual se puede observar que aunque sea un perro blanco, producto de la sombra de la imagen se clasifica muy oscuro. Este tipo de problemas no se pueden solucionar con los métodos utilizados durante este trabajo, aunque abren el debate a un trabajo muy interesante.
Finalmente, como final, se muestra a continuacion una imagen llamativa, donde el fondo, luego del recorte, es el que importa y predomina, ya que el perro queda fuera del recorte. Esto se debe a la suposición fuerte de que el perro se encuentra en el centro de la imagen. Esto se puede solucionar con un algortimo que reconozca el perro antes de hacer el análisis. Queda como trabajo propuesto en una extensión del proyecto.

El código utilizado para esta sección se puede encontrar aquí.
Trabajo Futuro
En el caso de que el trabajo el ramo continuara, se presentan ciertos temas que serían tocados en un futuro para mejorar los resultados obtendios durante este trabajo.
- Inicialmente, se podría trabajar con una red neuronal pre-entrenada, de manera tal que conociendo razas, colores y perros etiquetados y ya analizados mediante intervención humana, se pueda determinar si un perro corresponde a una cierta raza, tiene ciertas características, es de cierto tamaño, etcera. Aunque se podrían obtener mejores resultados, se debe trabajar mucho para que estos resultados lleguen a fin.
- También se pueden mezclar los métodos utilizados, ya que no se realizó PCA con el método del histograma, no se utilizó HOG con la afirmación fuerte de que el animal está en el centro de la pantalla, entre otros.
- Se podrían utilizar otros métodos de Clustering, como el Agglomerative Clustering, claro que teniendo en cuenta las implicaciones que se tiene al usar este tipo de entrenamiento.
Conclusiones
Dentro del contexto de lo realizado durante este trabajo durante el semestre, se puede concluir que el análisis de datos para obtener información y material de estudio es muy relevante y útil para el uso en las empresas y la vida cotidiana, ya que puede ofrecer herramientas y visiones de estas que en una primera revisión e intervención sobre los datos quizá no se obtengan.
Refiriendose al proyecto realizado, se puede concluir que se pudo extraer características importantes de las imagenes obtenidas de la base de datos, además de que estas características se pueden comercializar, por ejemplo, al conocer el color de un perro, se puede ofrecer a la persona ropa, productos de limpieza, entre otros, que son exclusivos para ese color o tipo de pelaje.
En el caso del primer experimento con PCA y HOG, una de las conclusiones más relevantes que se observa es advertir los límites que tienen los algoritmos y lo que pueden conseguir estos para ciertas tareas. En este caso se realizó una tarea de alta dificultad que consistía en conseguir características relevantes en imágenes de alta definición que entre clases eran altamente variables y además cada imagen al mismo tiempo podía tener una gran cantidad de objetos o outliers que dificultaban o agregaban ruido al problema.
De los algoritmos anteriormente señalados, se concluye que estos pudieron obtener características generales, principalmente color y contexto de cada imagen. Aunque se intentaron algoritmos basados en formas de la imagen o gradientes de esta (HOG) no se obtuvieron resultados, esto principalmente por las formas altamente variables que se pueden encontrar una imagen. Una posible solución es utilizar modelos que son exitosos en estas tareas, como redes neuronales convolucionales de forma supervisada utilizando una red preentrenada, así utilizar las características aprendidas por esta red para realizar la clusterización. Notar que en el proyecto si se intentó utilizar redes neuronales convolucionales pero de forma no supervisada, está es una tarea más dificultosa y a esto se le atribuye la obtención de buenos resultados utilizando esta metodología, en códigos anexos se pueden observar las implementaciones en Tensorflow de estos algoritmos.
Por parte del trabajo con los histogramas, aunque se pueden obtener datos y características muy claras de esots, se puede observar en el primer trabajo que es muy notoria la importancia e influencia del fondo en este contexto, como por ejemplo, cuando el perro ocupa un 10% o menos de la imagen analizada.
Por otra parte, al momento de recortar la imagen, se pueden observar mejores resultados, pero estan muy cesgados al centro, dejando toda la responsabilidad en el centro de la imagen, dejando de lado los perros que estaban hacia un lado, o que tienen algun tipo de vestimenta.
Como parte final, se puede concluir que se cumplieron los objetivos, no en su totalidad, pero si fueron cumplidos en cierta parte. El hecho de que se pudieron extraer características aunque de forma forzada, nos da un parámetro que puede ser comercializable y es de utilidad, tanto para las empresas como para los dueños de mascotas.