Educación en datos:¶
¿Una oportunidad de mejora?¶
Jorge Ignacio del Río
Felipe Flores
Marcelo Jiménez
Introducción¶
La educación, es uno de los temas más trascendentales a nivel país, tanto que es unos de los principales tópicos de noticias y discusiones políticas. Otro importante input a la motivación, fue un estudio de la OCDE en 2016, el cual determinó que Chile está en el top 10 de los países donde la condición socioeconómica afecta al rendimiento del estudiante. El mencionado estudio fue el puntapié que se necesitaba para empezar con un estudio del tema, realizando minería de datos al dataset correspondiente para así poder apreciar la realidad Chilena en materia de educación.
En un comienzo (hito 1) se trabajó con un dataset del gobierno de Canadá, el cual tenía un gran volumen de información pero muy diferente a la realidad local. Finalmente se terminó estudiando el dataset entregado por el gobierno de Chile del año 2016, que reunía la información de más de 3 millones de estudiantes Chilenos. A partir de esta información, el proyecto se enfocó en encontrar los factores que pueden influir en el rendimiento de un estudiante, poniendo a prueba nuestras hipótesis planteadas.
Hito 1¶
Descripción de los datos y exploración inicial.¶
El titulo del primer dataset es: “Unemployment rates of population aged 15 and over, total and with Aboriginal identity, by educational attainment, Canada”. Fue conseguido en la página gubernamental de canadá:
https://open.canada.ca/data/en/dataset/9b2c360c-310e-48a4-8351-fce63d674bee.
El dataset contiene 260 filas y 7 columnas, las cuales designan el año de la muestra, el grupo correspondiente (Canadiense o perteneciente a etnia aborigen), el nivel de educación (contempla desde educación básica incompleta hasta educación universitaria, considerando además títulos y diplomas no universitarios), y el porcentaje de desempleo del grupo.
Los datos provienen de la Encuesta de Fuerza de Trabajo “ Labour Force Survey (L.F.S.)”
La tasa de desempleo está calculada ocupando el promedio mensual desde Enero a diciembre. Fuente: https://open.canada.ca/data/en/dataset/1644371c-f190-41b2-86cc-0352d0954352
El segundo dataset que utilizamos es “Education Highlight Tables: Highest level of Educational attainment (detailed) by sex and selected age groups, for Canada, provinces and territories, census metropolitan areas and census agglomerations, 2016 Census” el cual contiene 756 filas, y contiene información detallada sobre la población de distintas localidades, especificando el sexo, año de muestra, rango de edad y el nivel educacional obtenido del grupo.
Temática o problemática central y describir cómo se abordará inicialmente.¶
El objetivo principal del proyecto es determinar cómo es afectada la educación que recibe una persona según el contexto social en que se encuentra, y cuáles son las consecuencias de haber recibido un nivel de educación específico.
Para abordar este problema nos apoyamos en las base de datos del gobierno de Canadá, que contiene un gran volumen de datos concernientes a educación, tal como el nivel de desempleo según tipo de educación (primaria, secundaria, universitaria…).
Para la primera parte del proyecto, que se enfoca en encontrar qué características afectan la calidad de la educación, nos concentramos en los datasets que incluyen el nivel de educación obtenido según población aborigen, edad, sexo y áreas metropolitanas y no metropolitanas entre otros.
Para la segunda parte del proyecto, que se preocupa de explorar las consecuencias de obtener cierto nivel educativo, nos enfocaremos en el ingreso promedio y el porcentaje de desempleo para distintas edades según grado académico alcanzado.
Para la exploración de los datasets utilizamos el software RStudio, de modo que podemos entrecruzar la información de varios sets de datos para conseguir encontrar más factores que los indicados únicamente en un solo set, además de ser capaz de graficar los datos para hacer más fácil la comparación e interpretación respecto a distintos sectores de la población.
Hito 2¶
Antecedentes¶
Se cambió el dataset ocupado en el hito 1 por una base de datos del gobierno de Chile. El dataset se puede descargar en el siguiente link: http://datos.mineduc.cl/dashboards/19881/informacion-de-rendimiento-academico/ . Se eligió el dataset de rendimiento escolar correspondiente al año 2016. El dataset incluye un pdf explicativo que recomendamos ver.
Esta base de datos nos entrega a todos los alumnos de enseñanza básica y media, junto con su colegio, curso, ubicación, residencia, jornada , porcentaje de asistencia, promedio y situación final del alumno (entre otros).
Con esta información queremos analizar la correlación entre estos atributos y el rendimiento del alumno (promedio). Nuestra hipótesis es que existen factores determinantes en el rendimiento del alumno, y queremos identificar cual es el conjunto de atributos que más influyen en el desempeño del estudiante.
Para esto se hará una limpieza del dataset en primera instancia, luego una exploración inicial de los datos en busca de gráficos y/o visualizaciones que permitan evaluar la validez de nuestra hipótesis, y finalmente se busca crear un clasificador que determine el rendimiento del alumno basandose en un conjunto de atributos presentes en el dataset.
Limpieza del dataset¶
Dado el gran volumen del dataset y su alta dimensionalidad se hizo una drástica limpieza, con el fin de manejar y testear los datos con mayor rapidez. Como no es de mayor interés esta parte no se incluirá una visualización del dataset original.
A continuación un resumen de la informacion eliminada en la limpieza:
Columnas:
- AGNO: Año escolar.(1)
- RBD: Rol base de datos del establecimiento.
- DGV_RBD: Dígito Verificador del RBD.
- LET_RBD: Letra del establecimiento.
- COD_DEPROV_RBD: Código del Departamento Provincial de Educación al que pertenece el establecimiento.
- COD_DEPE: Código de Dependencia del Establecimiento (2).
- ESTADO_ESTAB: Estado del establecimiento.(3)
- COD_TIP_CUR: Índice de tipo de curso
- COD_DES_CUR: Descripción del curso (solo aplica para enseñanza media TP).
- COD_RAMA: Código de rama (sólo media técnico-profesional y artística)
- COD_SEC: Código de sector económico (sólo media técnico-profesional y artística)
- COD_ESPE: Código de especialidad (sólo media técnico-profesional y artística)
- SIT_FIN_R: Situación de promoción al cierre del año escolar, con indicador de traslado.(4)
Filas:
- Se eliminó toda la educación de Adultos. Es decir todos los datos con COD_ENSE_2 = {3,6,8}
- Se eliminó la informacion de todos los establecimientos que no estuviesen funcionando. Es decir todos los datos con ESTADO_ESTAB != 1.
- SE ELIMINÓ ADEMAS LA EDUCACIÓN BASICA DE NIÑOS, con el fin de alivianar la carga del dataset a los computadores y poder trabajar con mayor eficacia. COD_ENSE_2={2}
- (1) Toda la columna contiene "2016".
- (2) Existe COD_DEPE_2 que agrupa a todos los establecimientos municipales en una categoría, por lo que se usó ese.
- (3) Se eliminó la informacion de todos los establecimientos que no estuviesen funcionando.
- (4) Existe SIT_FIN que no indica el traslado, por lo que se usó ese.
El dataset limpio se presenta a continuación:
import pandas as pd
Rendimiento = pd.read_csv("Rendimiento2.csv",sep=",")
Rendimiento[:6]
Exploración de los datos¶
Para chequear en primera instancia la validez de nuestra hipótesis se hizo una exploración inicial del dataset. Se busca crear visualizaciones que permitan comprender las relaciones entre las columnas de interes y el rendimiento.
Se asumió que las columnas de interés, es decir, aquellas que probablemente tienen una correlación con el rendimiento de los estudiantes son las siguientes:
- Región, Provincia y Comuna del Establecimiento (cod_reg_rbd / cod_pro_rbd / cod_com_rbd)
- Region y Comuna de residencia del alumno (cod_reg_alu / cod_com_alu)
- Dependencia del Establecimiento (cod_depe2)
- Ruralidad del establecimiento (rural_rbd)
- Jornada de clases (cod_jor)
- Porcentaje de Asistencia (asistencia)
Ubicación del Establecimiento¶
Comuna del Establecimiento vs Repitencia de estudiantes
Para las comunas con más de 100 alumnos registrados se muestra a continuación el Top 15 de las comunas con mayor repitencia.
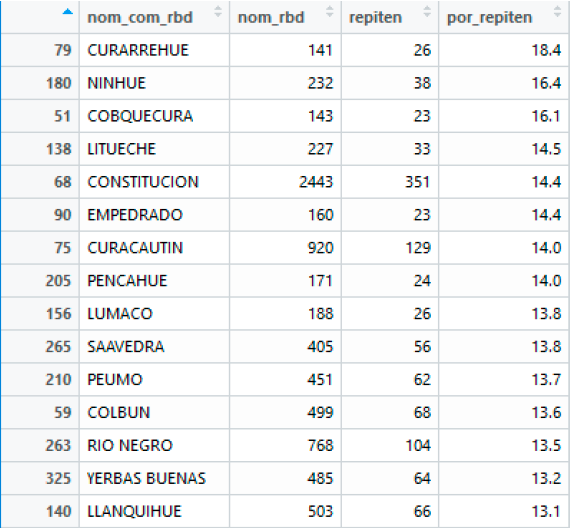
- Por_repiten: corresponde al porcentaje de repitencia
- Nom_rbd: corresponde al total de alumnos en la comuna
- Repiten: alumnos que repiten por comuna.
Para las comunas con más de 100 alumnos inscritos se muestra a continuación el Top 15 de comunas con menor repitencia.

- Por_repiten: corresponde al porcentaje de repitencia
- Nom_rbd: corresponde al total de alumnos en la comuna
- Repiten: alumnos que repiten por comuna.
Para las comunas con más de 100 alumnos inscritos se obtuvo lo siguiente:
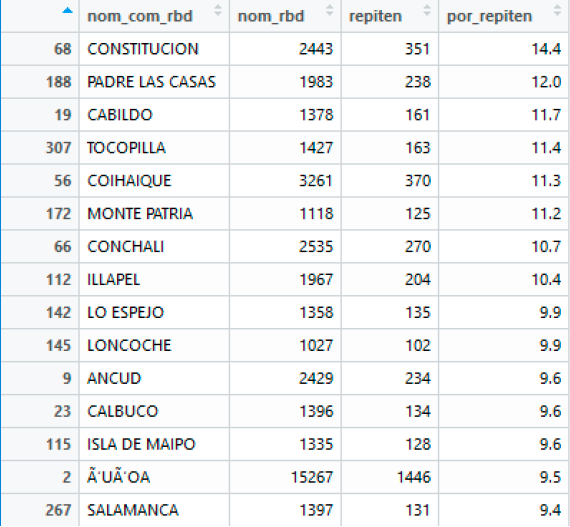

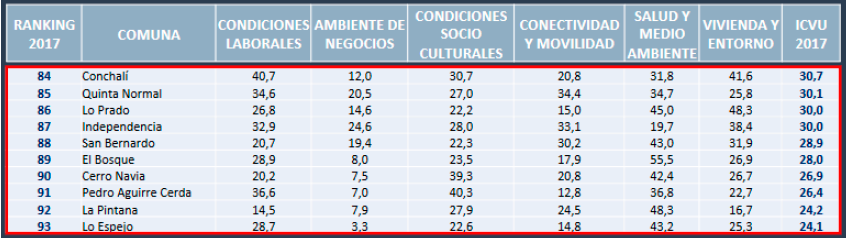
Se debe destacar que Las Condes, Vitacura, Providencia, Lo Barnechea y Con con, se encuentran entre las 10 comunas con mejor ICVU del país (ver tabla 5), y ademmás se encuentran dentro del ranking de las comunas con menos porcentaje de repitencia considerando comunas con mas de 1000 estudiantes inscritos (ver tabla 4).

Siguiendo la tendencia se destaca que las comunas de Conchalí y Lo espejo que se encuentran en las comunas de menos porcentaje de aprobación (Ver tabla 3), se encuentran en el ranking de las 10 comunas con peor ICVU a nivel país (Ver tabla 6).
Dependencia del Establecimiento.¶
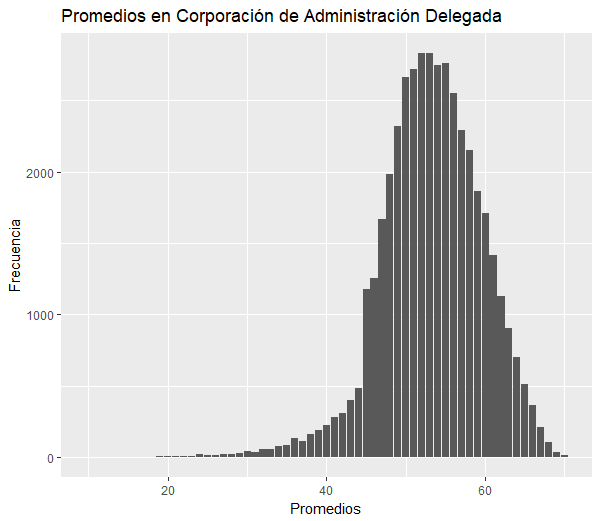
Se tienen 4 categorías de establecimientos: Municipales, Particular Subvencionado, Particular Pagado y Corporación de Administración delegada.
Esta ultima categoría aplica cuando el Ministerio de Educación Pública entrega la administración de determinados establecimientos de Educación Técnico Profesional de carácter fiscal a instituciones del sector público, o a personas jurídicas que no persigan fines de lucro.
Se estudió como se distribuyen los promedios en estos establecimientos y la situación final de los alumnos.
Del total de estudiantes:
- Aprueban: 818.073 (93% del total)
- Reprueban: 58.037 (7% del total)
A continuación se muestran los resultados:
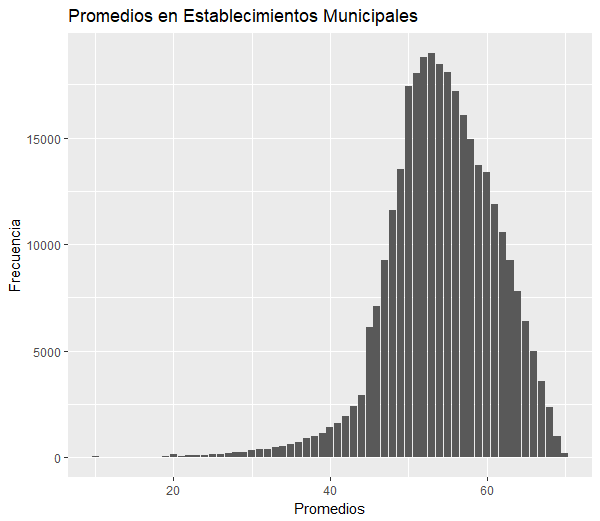
- Reprueban: 26. 578
- Lo que corresponde a un 8% del total de alumnos de 1ero a 4to medio de colegio municipal, y además corresponde al 45% del total de reprobados.
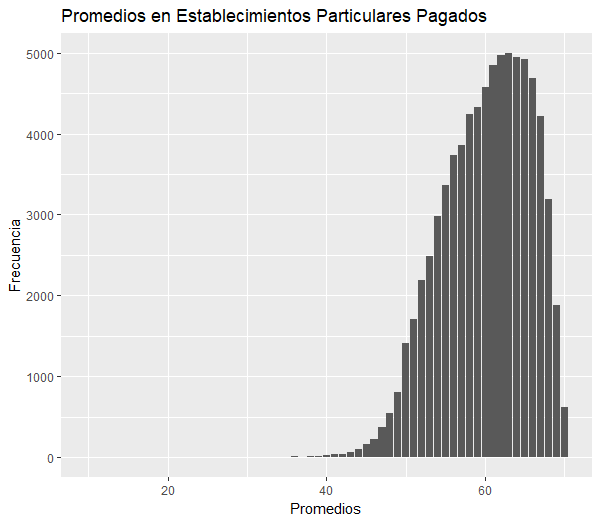
- Reprueban: 1.304
- Lo que corresponde a un 1,7% del total de alumnos de 1ero a 4to medio de colegio particular pagado, y al 2% de todos los reprobados.
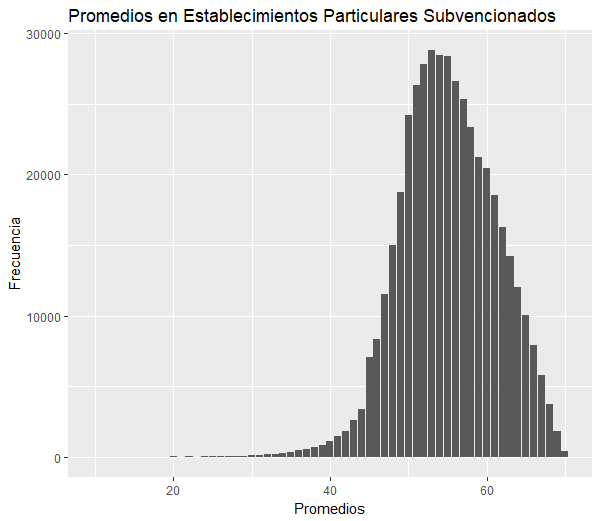
- Reprueban: 26.509
- Lo que corresponde a un 5% del total de alumnos de 1ero a 4to medio de colegio particular y al 46% del total de reprobados.
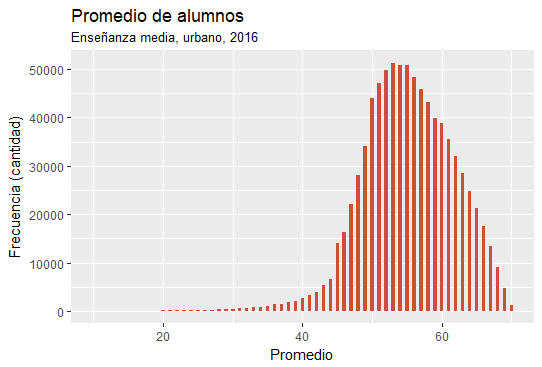
Ruralidad del establecimiento¶
El dataset incluye un atributo de ruralidad referido al establecimiento. A continuación se muestran distintos gráficos que muestran la distribución de promedios en establecimientos urbanos y rurales.

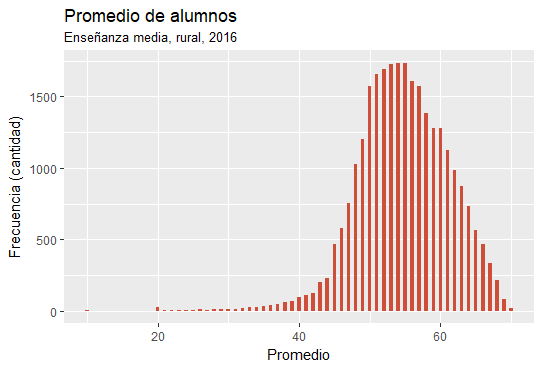
Asistencia del estudiante¶
A continuación se muestran los gráficos resultantes de comparar el porcentaje de asistencia de los alumnos con su promedio de notas.

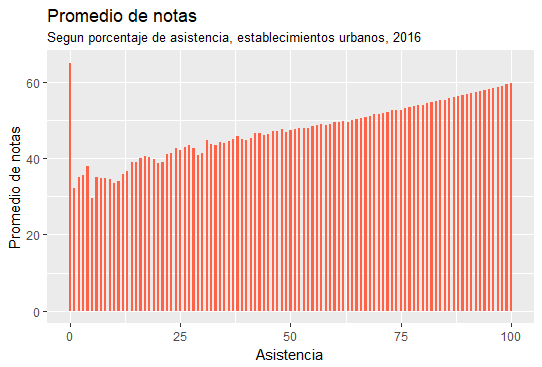

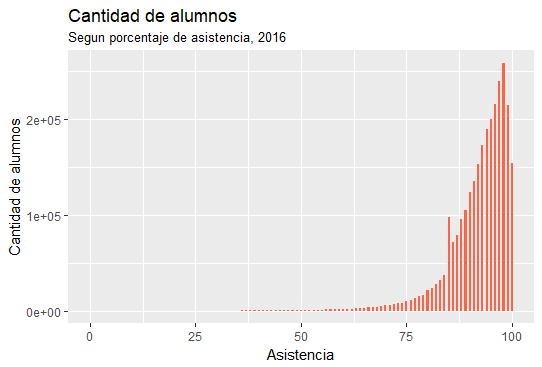

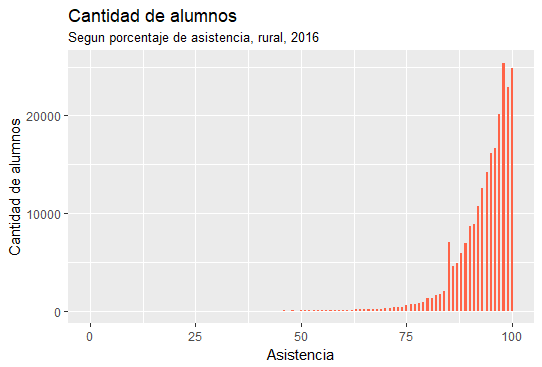
Hito 3¶
Terminada la exploración de los datos en el hito 2, se procede en este hito a realizar un clasificador. A través de los factores económicos y sociales presentes en los atributos del dataset, se desea identificar el rendimiento del alumno. Para así comprobar una relación de causalidad entre la situación socioeconómica del alumno, y su rendimiento escolar. En otras palabras, queremos medir "El peso de la Cuna" e identificar sus componentes principales.
Se realizó una segunda limpieza del dataset. Se eliminaron las columnas de códigos identificatorios, código de región y código de provincia del alumno y del establecimiento. El dataset final se muestra a continuación:

Resultados¶
Se utilizó el clasificador Naive Bayes. Se le agregó al dataset una columnna de Clases. Donde la clase A se le asigna a los alumnos con promedio entre 7.0 y 6.0, la clase B de 6.0 a 5.0, la clase C de 5.0 a 4.0 y la clase D de 4.0 a 0.0.
Con esta nueva columna se exploró la distribución de los datos en las clases. A continuación se muestran los resultados.

En el anterior gráfico el color rojo simboliza la clase A, el color verde la clase B, el color azul la clase C y el color celeste la clase D. El tamaño del rectángulo nos da muestra de la proporción de estudiantes que tienen un determinado rendimiento. Esto está separado por el género del alumno, donde la columna izquierda son los estudiantes de sexo masculino y la izquierda sexo femenino. De esto se concluye que la proporción de mujeres que tienen un rendimiento de clase A es mayor que la proporción de hombres. Mientras que la proporción de estudiantes de clase D (mal rendimiento) de sexo masculino es claramente mayor que la proporción de estudiantes clase D de sexo femenino. En tanto para la clase B y C vemos similares rendimientos donde la mujer sigue siendo superior.

En el anterior gráfico el color rojo simboliza la clase A, el color verde la clase B, el color azul la clase C y el color celeste la clase D. El ancho de los rectángulos nos muestra la proporción de tipo de establecimientos: La primera columna (de izquierda derecha) corresponde a colegios municipales; la segunda columna corresponde a colegio subvencionado (aquí podemos apreciar que casi la mitad de los estudiantes asisten a educación subvencionada); la tercera corresponde a colegios particulares pagados (una minoría de estudiantes asisten a estos colegios); y la última corresponde a administración delegada la cual no es de interés de estudio. La altura de los rectángulos nos muestra la proporción de estudiantes que pertenecen a cada clase dependiendo del tipo de establecimiento: En educación municipal la mayoría de los estudiantes se encuentra en la clase D, lo que en comparación con los otros tipos de establecimientos es notoriamente más alto; en educación subvencionada la proporción de las clases del rendimiento de estudiantes es más similar, destacando que hay una mayor proporción de estudiantes con rendimiento de clase A en contraste con la educación municipalizada; finalmente en la educación privada se ve la mayor diferencia, donde en proporción los estudiantes pertenecientes a la clase A es casi la suma de las proporciones de los 2 tipos de establecimientos anteriores, dando muestra de la desigualdad existente.
Clasificador¶
Finalizada esta segunda exploración de datos se procede a aplicar el clasficador Naive Bayes. Los resultados se muestran a continuación:

Se puede apreciar un nivel de Acuracy de 0.5, lo cual nos idica que el clasificador no fue capaz de predecir con certeza las clases a las que pertenecían los estudiantes del dataset. Esto se corrobora al analizar las estadísticas por clase. Se observa que las clases C y D tienen las peores métricas. Esto quiere decir que el dataset no tiene suficiente información para distinguier entre ambas clases. Esto se explica por el hecho que las componentes que aportan mayor variabilidad al dataset son el sexo del alumno y si pertenece o no a un colegio particular, por lo tanto el clasificador probalemente decide en base a esos parámetros e ignora el resto.

En la matriz de confusión se hace claro el hecho que las clases C y D no fueron consideradas por el clasificador. La totalidad de los datos fueron predichos en las clases A Y B, dejando las filas C y D en 0. La fuente de este error está ligada al dataset, al parecer no existen atributos suficientes para que el clasificador pueda identificar estas clases.
Conclusión¶
Del trabajo semestral se concluye que el clasificador usado solamente utilizaba los atributos de género del alumno y el tipo de establecimiento, ya que estos eran los componentes que aportaban mayor variabilidad al momento de definir la clase del estudiante. En el tipo de establecimiento es donde notamos la mayor diferencia al momento de definir la clase del alumno. Sumado lo anterior se estudió las comunas con los ratios más altos y más bajos de repitencia, dónde las que tienen el ratio más bajo corresponden a sectores de Chile que tienen un índice de calidad de vida más alto de acuerdo al ranking ICVU del 2017. En contraste tenemos a las comunas con más alto ratio, dónde muchas se encuentran entre los peores sectores del país en cuanto a la calidad de vida.
Con lo visto, se comprueba una de las principales hipótesis: la posición socioeconómica influye en el rendimiento del estudiante, donde los estudiantes de más bajo recursos tienen una mayor probabilidad de tener un mal rendimiento siendo el contraste opuesto a la suerte que viven los que asisten a educación privada.
Se espera que con trabajos como este se genere conciencia de la educación desigual del país, especialmente en espacios del área ingenieril, donde gracias a estudios de esta índole se comience a dar soluciones concretas para disminuir la brecha de desigualdad existente.