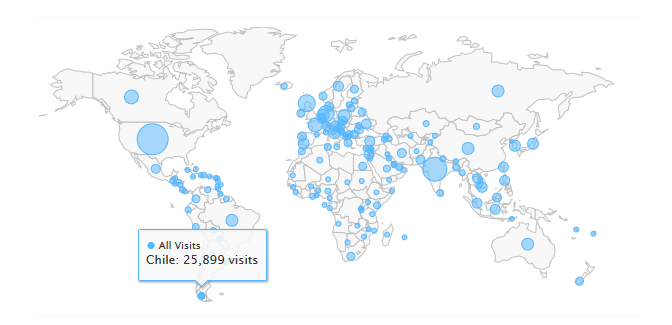
Los datos utilizados para el proyecto fueron extraídos de Stack Overflow Data , El servicio web de Google BigQuery permite realizar almacenamiento y consultas de conjuntos de datos masivos con billones de registros.
Para el proyecto se seleccionó la base de datos de Stack Overflow, esta base de datos esta conformada de 16 tablas, de las cuales consideramos como relevantes son las preguntas, respuestas, tags, comentarios y usuarios. En este enlace se pueden visualizar los atributos de las tablas con más detalle. A continuación se muestran la cantidad de registros por tabla
| Tabla |
Cantidad Registros |
users |
7'250.739 |
| tags |
49.306 |
| post_questions |
14'015.379 |
| post_answers |
22'046.899 |
| comments |
58'159.095 |
Con la finalidad de crear un dataset para el proceso de análisis se extrajeron los datos de preguntas realizadas desde Enero de 2016 hasta Junio de 2017.
Para entender un poco más del significado de estos atributos, recurrimos a la
Wiki de StackOverflow. Las preguntas, respuestas y usuarios tienen un puntaje o score que suma cuando un usuario da un voto y también puede disminuir, además del número de visitas, la fecha de creación y respuesta de la pregunta y reputación del usuario.
Como exploración inicial visualizamos los tags que más se usan en las preguntas:
import csv
from wordcloud import WordCloud
import matplotlib.pyplot as plt
reader = csv.reader(open('/dm_project/tags_count_tags.csv',
'r',newline='\n'))
d = {}
for k,v in reader:
d[k] = int(v)
wordcloud = WordCloud(width=900,height=500, max_words=700,relative_scaling=1
,normalize_plurals=False).
generate_from_frequencies(d)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

La imagen muestra que la mayor parte de las preguntas realizadas en el sitio correponden a lenguajes de programación como: javascript, java, android, python, c#, php, c++
Para el dataset de exploración seleccionamos las preguntas que tienen el tag java y python.
Se eliminaron los campos que no agregan valor a el análisis como id's y se reemplazaron los valores nulos, que eran datos vacíos por cero en los campos numéricos.
select q_id,
case when a_comment_count is null then 0 else a_comment_count
end as a_comment_count,
FORMAT_UTC_USEC(a_creation_date) as a_creation_date,
FROM
[fleet-automata-177802:filtros_stackoverflow.answer_question]
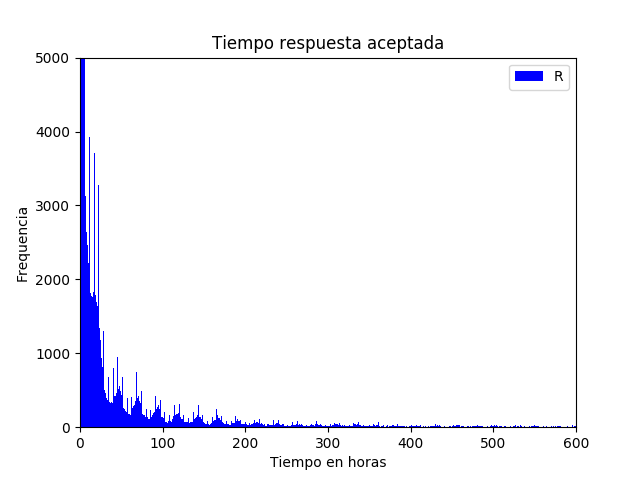
Con la finalidad de observar el comportamiento de las respuestas a las preguntas en el tiempo se creó un gráfico de frecuencias. En el primer gráfico se puede observar la frecuencia con la que las preguntas reciben su primera respuesta, la cual en su mayoría es en la primera hora, sin embargo existen preguntas que se responden después de un día incluso meses. Código fuente
El comportamiento de la primera respuesta y la respuesta aceptada aparentemente es similar, esto indica que en la mayoría de los casos la primera respuesta es la seleccionada.
Otra de las variables analizadas fue el número de respuestas por pregunta. Obteniendo como resultado una diferencia de el 25% entre las preguntas con respuesta y sin respuesta seleccionada. Se puede observar además que existe al menos una pregunta que tiene más de 20 respuestas. Código fuente

Para visualizar la relación entre los atributos cuantitivos del dataset se creó una visualización multidimensional. Los atributos que inician con 'a_' corresponden a la suma total de todas las respuestas no aceptadas de una pregunta, los que incian con 'q_' son los atributos de las preguntas, los tiempos corresponden a la primera respuesta (time_first_a), la última (time_last_a), y el tiempo de la respuesta aceptada (time_atd), además se contempló los atributos de la respuesta aceptada (atd_comments,atd_edit,atd_score). El atributo particular edit corresponde a la cantidad de respuestas editadas. Código fuente
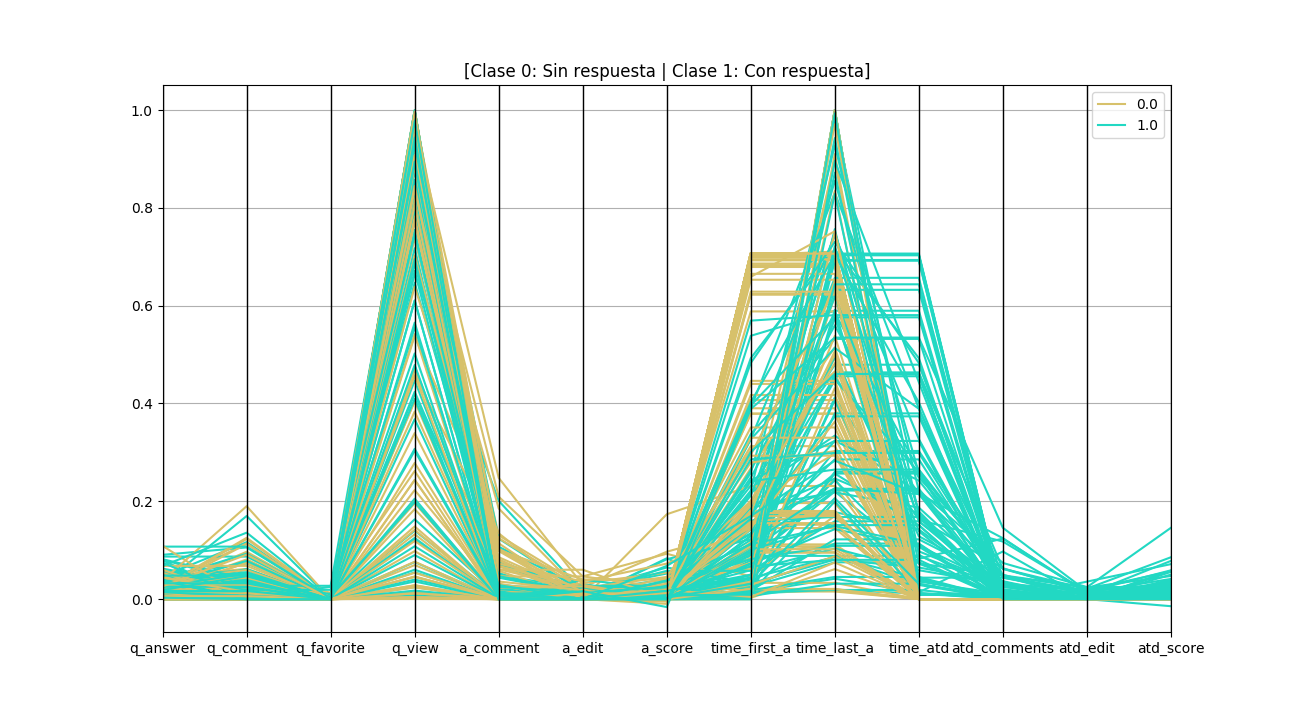
Del gráfico anterior se puede concluir que existen atributos no tienen una relación determinante con la clase de pregunta. Existe una cantidad apreciable de preguntas cuyas respuestas fueron emitidas después de un largo tiempo y que no fueron seleccionadas. Como se había visto anteriormente la primera respuesta es aceptada.
Se colocaron los atributos de numero de comentarios, edicion y score de la respuesta aceptada para compararla con el valor de las respuestas no aceptadas y se puede observar que la respuesta aceptada tiene más comentarios que la suma de los comentarios de todas las respuestas no aceptadas, de igual manera la cantidad de ediciones y el score.