Introducción¶
La música es una de las formas de arte más antigua, la cual ha evolucionado a través de los siglos sumando una inmensa cantidad de obras complejas y únicas. Debido a que ha existido durante tanto tiempo y al haber estado presente en muchas culturas y épocas, hoy en día podemos encontrarnos con diversos tipos de estilos e instrumentos utilizados, a lo cual se le ha llamado géneros musicales.
Este tipo de clasificación, si bien es muy útil a la hora de poder agruparla según una época específica o encontrar música para una situación determinada; y descubrir melodías nuevas en caso de no conocerlas, plantea un problema debido a que las bases mismas de los géneros son confusas, incluso para los expertos.
Al haber pasado por un proceso evolutivo, la nueva música muchas veces se ha basado en estilos anteriores, haciendo que la diferencia entre géneros sea difusa en ocasiones, obteniéndose canciones con géneros múltiples o incluso sin un género preexistente si es que es innovadora.
Gracias a las herramientas existentes en la actualidad se pueden obtener las diversas características propias de una canción y mediante éstas se intentará obtener, de forma más objetiva, el género de una canción y se analizarán los resultados comparándolos con el género original al cual pertenece.
Esto puede ser de ayuda para que las personas puedan encontrar canciones mediante géneros de una manera más precisa y que dicha asignación se realice automáticamente a las melodías, ayudando también al software de sugerencias en aplicaciones como Spotify y ITunes.
Objetivos¶
Los objetivos del proyecto se pueden dividir principalmente en 2:
- Obtención automatizada de géneros musicales a partir de las propiedades de la canción.
- Generación de géneros mediante clusters y su comparación con los géneros originales.
Problemas¶
Si bien las personas pueden clasificar una canción con solo escuchar algunos segundos de esta, dicha clasificación puede variar de persona a persona.
Podría llegar a ser razonable clasificar con solo personas, pero debido a la cantidad actual de canciones, no solo sería un proceso tedioso, sino también la suma de posibles errores de clasificación al finalizar el proceso sería enorme.
Las computadoras actuales pueden procesar una gran cantidad de información en muy poco tiempo comparado con las personas, pero, al menos en el caso de los géneros musicales, no es directa su obtención con solo el archivo que corresponde a la canción misma.
Las canciones pueden verse como ondas de energía y, por medio de herramientas especializadas, se puede extraer de estas parámetros relativamente estándares. Pero los parámetros relevantes, según distintas fuentes, suelen variar, por lo que es aún más complicado elegir la herramienta para la extracción de estas y seleccionar de entre los parámetros en cuestión.
Afortunadamente existen algunos dataset que contienen dichos parámetros ya asociados a las canciones, pero el número de estos no es muy grande, y el principal problema es que a muchos les falta la característica que queremos evaluar, el género de la canción. Si bien algunos poseen este atributo, en muchas ocasiones se observó que, o poseían más de un género asociado, o tenían géneros muy particulares y extraños (como "anime" o "estudio") o simplemente carecían de dicha etiqueta.
Debido a estas dificultades se abordó el problema de distintas formas a través de los hitos, obteniendo resultados variados, como se ve a continuación:
Hito l: SonicApi¶
Dataset¶
Para el primer hito se utilizó el dataset GTZAN Genre Collection , una colección de 1000 pistas de audio de 30 segundos distribuidas equitativamente en 10 géneros musicales. Las pistas son muestras de canciones provenientes de diversas fuentes como CD’s, radio, entre otras con el objetivo de representar diversas condiciones de grabado y de calidad.
Los géneros que clasificaban a las canciones eran: blues, música clásica, country, disco, hip-hop, jazz, metal, pop, reggae y rock.
Para la obtención de estadísticas de las canciones se utilizó la página SonicApi, una aplicación de procesamiento de audio basada en la nube que provee su servicio a través de peticiones HTTP. Donde se debe enviar un archivo de audio y un método de procesamiento, y una vez analizada la canción se procede a descargar los resultados.
La API mencionada entrega diversas opciones para extraer información de las canciones, de las cuales se eligieron las siguientes para conformar el dataset:
- Tempo:
- clicks_per_bar: Número de pulsos por barra (segmento de tiempo)
- overall_tempo: Medida del tempo percibido en bpm
- overall_tempo_straight: Medida del tempo obtenida con una computación diferente
- click_marks: Una lista de muestras obtenidas de la pista de audio. Cada una de estas entrega información sobre el bpm, la probabilidad del click, el tiempo en que fue marcado y si es un pulso inicial.
- Intensidad
- programme_loudness: La intensidad del audio en LU (unidad de volumen).
- loudness_range: El rango de la intensidad presente en la pista.
- momentary_loudness_max: La intensidad máxima integrada a lo largo de un segmento de 0.4 s
- shortterm_loudness_max: La intensidad máxima integrada a lo largo de un segmento de 3 s -truepeak_max: Amplitud máxima registrada medida en dBFS.
- Melodía
- key: El nombre de la llave presente en la muestra.
- key_index: La llave extraída representada como un índice de un arreglo de 24 valores.
- tuning_frequency: La frecuencia de la altura de concierto A4.
- notes: Una lista con notas extraídas de la canción, cada una de estas posee información sobre su altura en midi, tiempo de inicio, duración y volumen
Análisis y resultados¶
Una vez obtenidas las estadísticas musicales de las canciones se procedió a realizar una exploración de estas. De este análisis se concluyó que, con los parámetros obtenidos era posible caracterizar un género, siendo algunos de ellos altamente representativos como lo son loudness_range en el jazz u overall_tempo en el country.
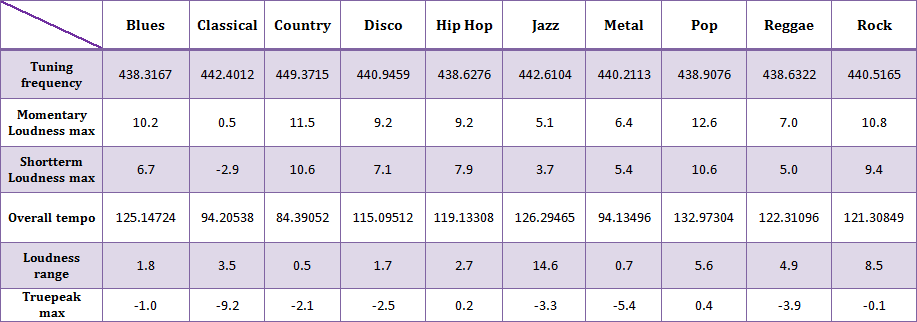
Con respecto a un análisis basado en los arreglos con información de los clicks promedios pertenecientes a los pulsos por minutos de cada género, se obtuvo que, a lo largo de las muestras, el bpm es capaz de identificar un género con una curva, la cual no posee mayores fluctuaciones entre sus valores. Esta caracterización es eficaz para géneros con pulsos por minuto muy particulares como lo son el pop y el country
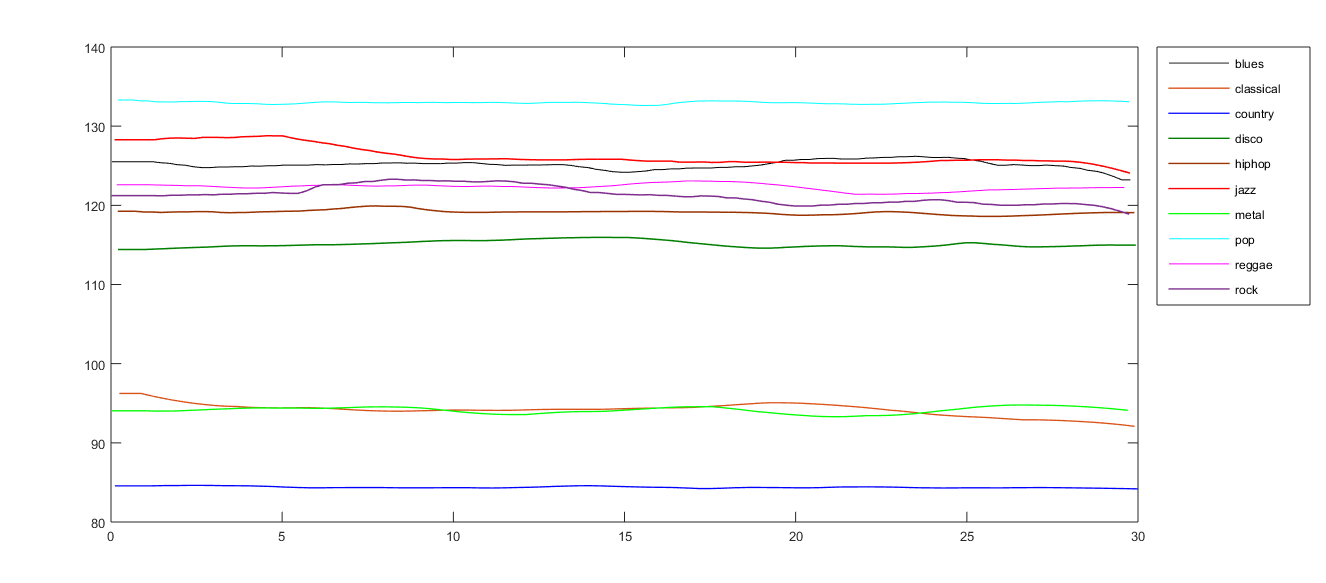
Aun así, si se analiza el bpm de canciones del mismo género se puede evidenciar que las curvas son más cercanas entre sí, pero no lo suficiente para establecer una relación directa.
A pesar que se pudieron obtener ciertos resultados con la exploración inicial de los datos, no se pudo continuar trabajando con este dataset debido a que la pagina SonicApi dejo de contestar requests, por lo que no se pudo obtener más estadísticas.
Hito ll: MillionSong¶
Dataset¶
En el segundo hito se decidió utilizar el dataset MillionSong Allmusic Genre, el cual constaba de 10000 canciones pertenecientes a 13 géneros diferentes.
En un análisis preliminar del DataSet se observó que los datos no se encontraban asociados a sus clases (o géneros) correspondientes, sino que los géneros de las canciones se encontraban en un .txt. Este txt asociaba el nombre del archivo de una canción con su género, por lo que se tuvo que realizar un "join" canción-género con ambos archivos para corroborar la cantidad de datos que poseían un género asociado.
Tras realizar el join se obtuvieron los siguientes resultados:
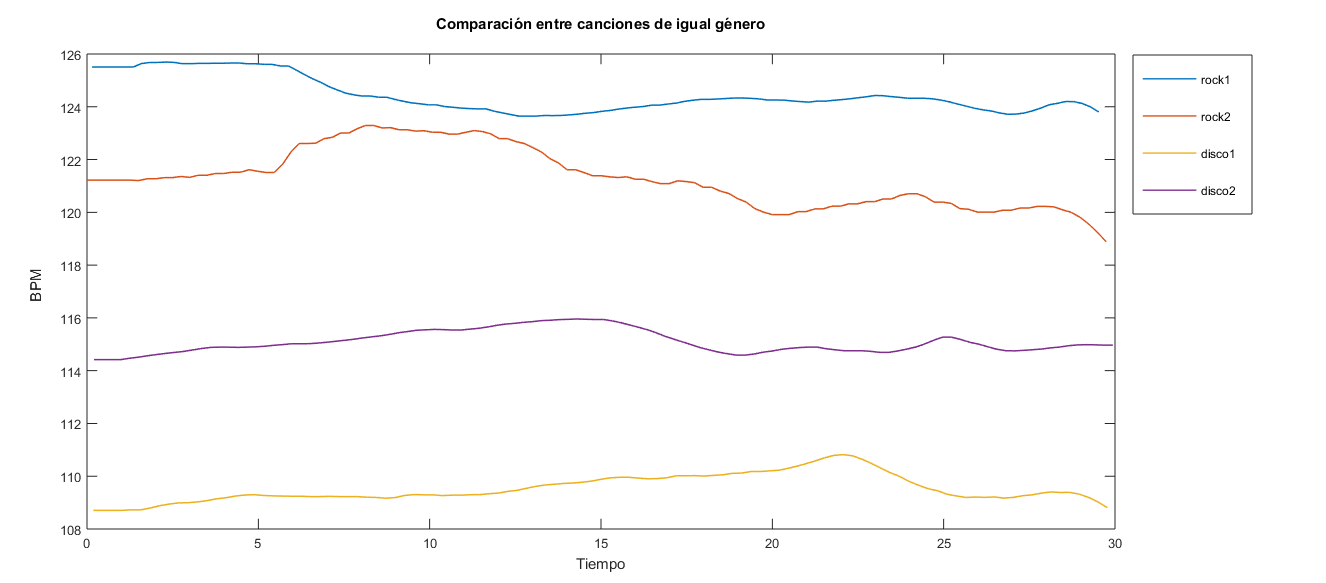
- "msd-topMAGD-genreAssignment.cls.txt": En este caso se obtuvo que de los 10000 datos solo 3699 tenían un género asociado. En el siguiente gráfico se observa la distribución de los datos entre las siguientes 13 posibles clases:
- 'Pop_Rock' corresponde a la clase 0
- 'Rap' corresponde a la clase 1
- 'Vocal' corresponde a la clase 2
- 'Electronic' corresponde a la clase 3
- 'Blues' corresponde a la clase 4
- 'RnB' corresponde a la clase 5
- 'Folk' corresponde a la clase 6
- 'Country' corresponde a la clase 7
- 'Jazz' corresponde a la clase 8
- 'New Age' corresponde a la clase 9
- 'Latin' corresponde a la clase 10
- 'International' corresponde a la clase 11
- 'Reggae' corresponde a la clase 12
Es importante señalar que el DataSet original presentaba más de 40 columnas (o características), por lo cual fue reducido solo a 8. Finalmente, cada dato poseía 9 características las cuales eran:
SongID: Indica el nombre del archivo que contiene los datos de la canción. Este es usado para relacionar la clase (o género) con la canción respectiva, tal y como se señaló previamente.
Duration: Indica el tiempo, en segundos, de la canción.
EndFadeIn: Indica el segundo en donde termina la intro de la canción.
Key: Indica la escala en la cual está escrita la canción, por ejemplo, llave de sol (la escala más conocida).
Loudness: Es un factor subjetivo dependiente de cada persona que escucha la canción. Este factor indica que tan "fuerte" es el sonido (va desde lo más suave a lo más ruidoso).
Mode: Indica si la canción está escrita en "escala" mayor o menor.
Tempo: Señala la velocidad de la canción. Se mide en beats por minutos.
Title: Es el título de la canción.
Genre: Señala el género de la canción. Este es un valor numérico donde cada número se relaciona con su respectivo género tal como se señaló más arriba, por ejemplo, 'Pop_Rock' es la clase 0.
Un aspecto importante a destacar del proceso de filtración de características corresponde al hecho de que varios datos numéricos asociados a una canción no eran unidimensionales, sino que eran vectores o matrices de datos por lo que, para simplificar el manejo de dichas propiedades se optó por eliminar estas características del DataSet y solo usar datos unidimensionales significativos.
Experimentos y resultados¶
Con el objetivo de dividir los datos en grupos significativos se decidió utilizar el algoritmo de clustering particional K-means. Como aspecto inicial de validación, se calculó el número correcto de clusters a utilizar en la experimentación mediante la obtención de la medida interna SSE.
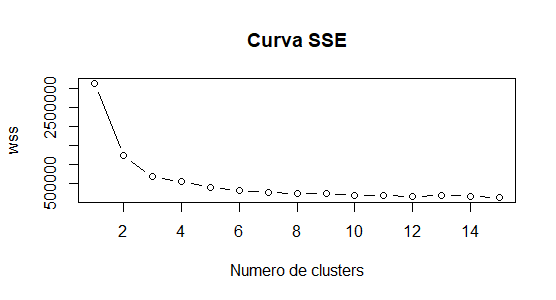
Utilizando la regla del punto de inflexión en la curva graficada, se obtuvo que el número de clusters a utilizar debía ser 3.
Luego se construyeron clústeres mono dimensionales de los parámetros loudness, tempo y key; de esta manera se podría observar como cada una de estas características de una canción particionan el conjunto de datos entre los clústeres.
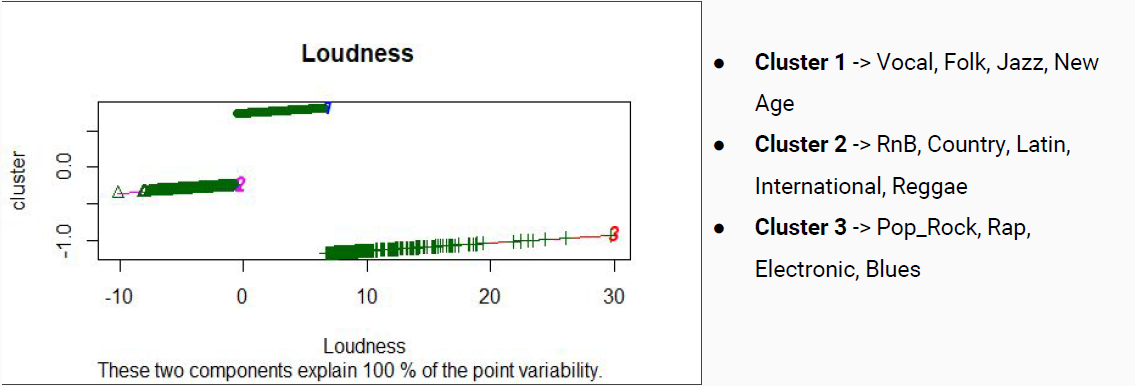
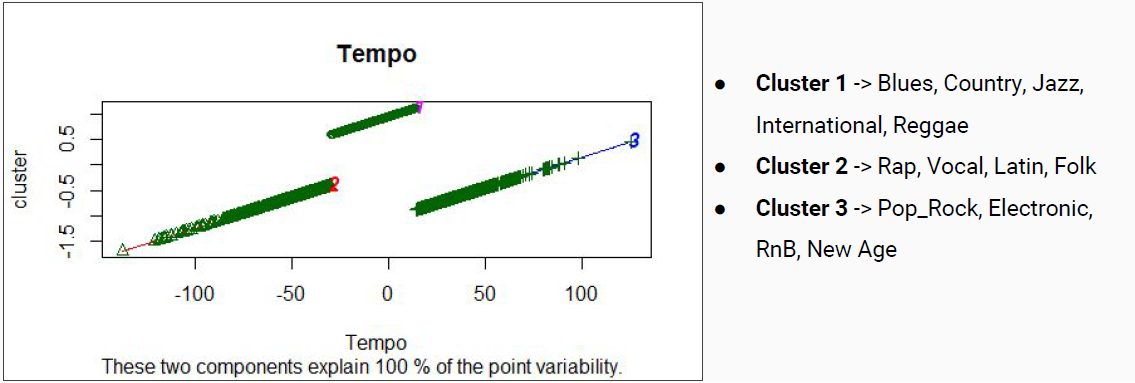
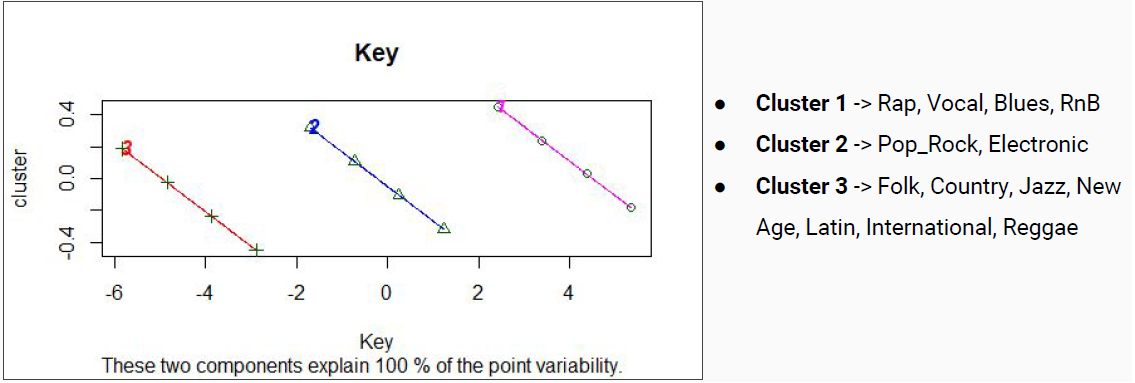
Finalmente se realizó un clúster multi-dimensional que consideraba como dimensiones todos los parámetros pertenecientes al dataset mencionados anteriormente:
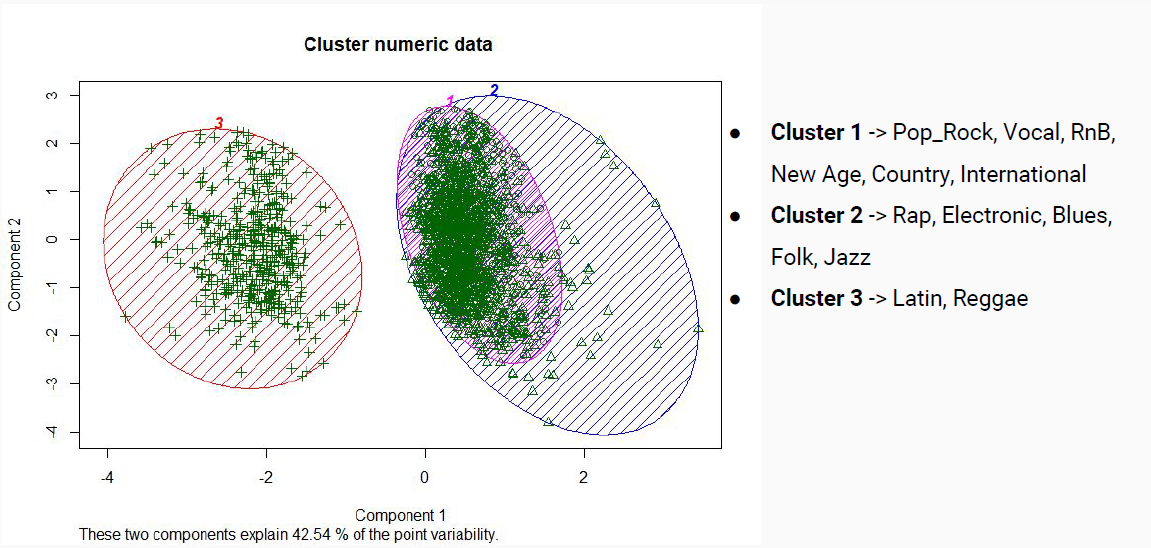
Graficando la distribución del clúster entre los diversos géneros se obtenía lo siguiente:
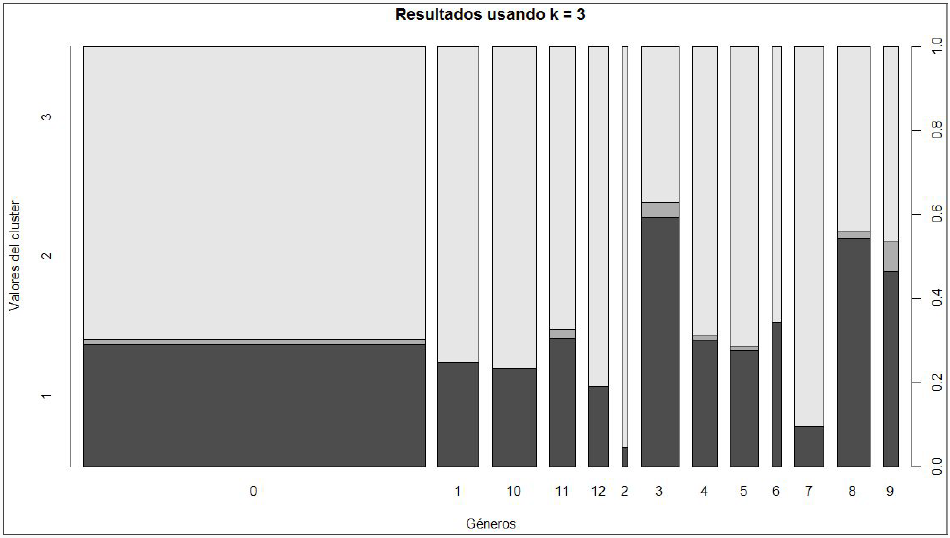
En general los resultados encontrados mediante los clusters en el hito 2 se alejaban de lo esperado, resultando en una clasificación por géneros muy distinta a la inicial debido a que se reparten las canciones de un mismo género original prácticamente entre todas las nuevas clases generadas.
Hito lll: AcousticBrainz¶
Hipótesis y preguntas de investigación¶
Para esta tercera iteración se tomó en consideración la ayudada brindada por uno de los compañeros del curso, el cual indicó que los puntos claves que permitirían clasificar una canción en algún género musical serían: Timbre, Duración (tiempo), Alturas e Intensidad.
A partir de lo anterior se propusieron las siguientes preguntas de investigación:
- ¿Se pueden clasificar los diferentes estilos musicales, utilizando características como Timbre, Altura, Intensidad, Tono y Ritmo?
- ¿Es posible clasificar los géneros musicales utilizando los métodos de Clustering, Árbol de decisión y Knn?
Con esto surgió la siguiente hipótesis:
"Se pueden clasificar los diferentes estilos musicales, utilizando los datos de timbre, altura, intensidad, tonalidad y ritmo con reducción de dimensionalidad mediante 3 criterios de clasificación (knn, árbol de decisión y clustering)".
Datos y análisis estadístico¶
Con la finalidad de poder dar respuesta a las preguntas planteadas anteriormente y validar o descartar la hipótesis establecida fue necesario hacer uso de otra base de datos dado que la anterior (la del hito 2) no presentaba las características que eran necesarias (timbre, altura, intensidad, tono y ritmo). A raíz de esto, se buscó un nuevo DataSet del cual fuese posible extraer los atributos ya antes mencionados llegando, de esta manera, al DataBase AcousticBrainz, el cual es un proyecto crowd source con el objetivo de recopilar información acústica para todas las canciones del mundo. Éste pesa 34 GB aproximadamente y se obtuvo de la página web: https://acousticbrainz.org/download.
En primer lugar, dado el gran tamaño de la base de datos, las canciones se obtuvieron leyendo cada 10.000 bytes del comprimido tar.bz y escribiéndolos en archivos. Una vez realizado lo anterior para una cantidad de datos, se separaron las canciones del archivo con saltos de línea utilizando, para esto, regex. Finalmente, se separaron cada una de las canciones en un json independiente (utilizando python) el cual contenía todas las características que presentaba el DataSet (más de 80 características).
Tras obtener más de 2000 archivos Json, estos se procesaron utilizando un programa realizado en python el cual permitía obtener las características del DataSet necesarias para representar el Timbre, Altura, Intensidad, Tono y Ritmo de una canción las cuales son:
- BPM: Son los beat por minutos. Estos representan el Ritmo de una canción. Cabe destacar que este atributo es importante dado que considera los beats, que es la unidad básica de la música y por ende es importante considerarlo como característica.
- Thpcp: Representa el Pitch o la Altura. Esta es la frecuencia del sonido y señala que tan agudo o grave es.
- Average_loudness/beats_loudness: Representa la Intensidad o Loudness. Permite diferenciar entre un sonido suave y uno fuerte.
- Spectral_strongpeak: Representa el Timbre y permite caracterizar un sonido diferenciándolos unos de otros.
- Chord_strength/key/scale: Representan el Tono. El tono es el grupo de timbre que forman la base de la composición musical.
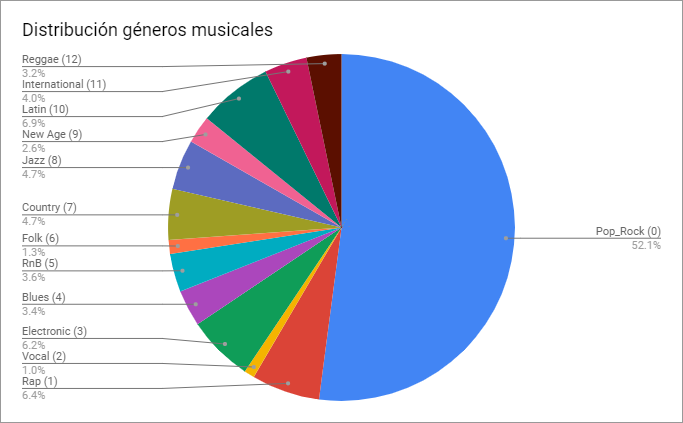
Mediante el procesamiento de los Json, se descartaron aquellos archivos que venían dañados (el json estaba incompleto y por ende no se podía leer) y aquellos que no presentaban la clase (género) asociado. Tras esto se obtuvieron solo 751 datos los cuales se dividieron en 122 clases diferentes. La distribución de estos se puede apreciar en el siguiente gráfico:
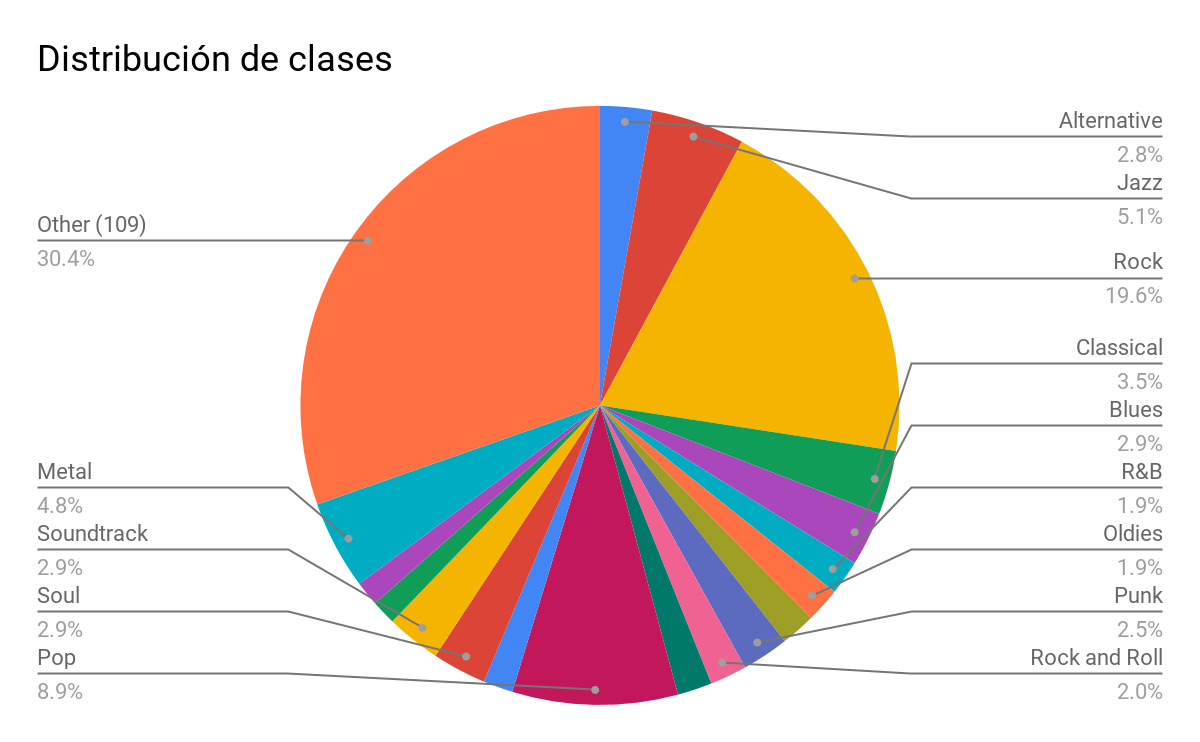
En el gráfico de torta se aprecian solo 13 de las 122 clases. Estas 13 clases son aquellas que contienen más de 10 muestras en el DataSet utilizado mientras que las restantes 109 clases se agrupan en "Other". Es posible notar, además, que la clase "Rock" es la que engloba gran parte de los datos que se poseen.
Durante el preprocesamiento de los datos, tras extraer los Json buenos y las características mencionadas anteriormente, se procedió a crear la base de datos a usar dado que se debían modificar algunos atributos dado que estos no eran cuantitativos (números) o eran multidimensionales, cuyas dimensiones dependían de cada dato y por ende podían ser diferentes en comparación a los otros. Para el caso de los primeros atributos se realizó lo siguiente dependiendo de cuál característica se trataba:
- Chord_key: Existían varias llaves válidas en el DataSet las cuales son: C, Em, G, Bm, D, F#m, A, C#m, E, G#m, B, D#m, F#, A#m, C#, Fm, G#, Cm, D#, Gm, A#, Dm, F, Am. Para cada una de estas llaves se asoció un número guardando la tupla en un diccionario lo que facilitaba el cambio de la llave de un dato a su valor numérico arbitrario estando el 0 asociado a la llave "C" y el 23 a la llave "Am" (en orden).
- Chord_scale: Existían dos tipos de escalas: minor, major; por lo que se asoció el 0 a la escala "minor" y el 1 a la escala "major".
- genre: Para este atributo habían cientos de géneros diferentes por lo que, en primer lugar, se procedió a disminuir dicha cantidad eliminando los géneros más extraños o menos conocidos (por ejemplo "dan", "chanson", etc), juntar en un solo género aquellos estilos similares (por ejemplo, todos las gamas de Pop solo en el género Pop) y agrupar los géneros iguales pero que estaban escritos de maneras diferentes (por ejemplo, R&B venía también como: "RnB", "R B", "r&b", etc). Tras esto, se procedió a crear un diccionario asociando a cada uno de los 122 géneros finales un número el cual sería usado como característica o clase en lugar del nombre del género como tal.
Por otra parte, había características multidimensionales tales como:
- Chord_strength, beats_loudness, Spectral_strongpeak: Estas características eran vectores de tamaño fijo, es decir, pese a la canción su tamaño era siempre el mismo dado que estos poseían el mínimo, el máximo, la media, la mediana y la varianza. Para utilizarlos como atributos se optó por colocar cada uno de estos valores como una columna (característica) independiente.
- Thpcp: Este atributo era un vector de tamaño variable por lo que era imposible realizar lo mismo que para los atributos mencionados anteriormente. Debido a esto, se optó por calcular las estadísticas básicas de este vector (mínimo, máximo, media, mediana y varianza) y colocar cada una de estas estadísticas como una característica independiente de cada canción.
Tras realizar cada uno de estos arreglos se obtuvo que cada dato se representaba por 8 atributos (los mencionados anteriormente) y, por ende, presentaban un total de 38 características (columnas) considerando un id que representaba a cada dato y su género.
Finalmente, se procedió a realizar los cálculos estadísticos básicos para observar la distribución de los datos. En la siguiente tabla se aprecian los datos obtenidos:
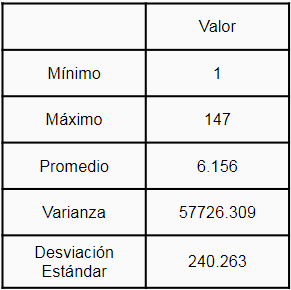
En la tabla anterior se observa una alta desviación estándar la cual supera con creces el promedio, mostrando que los datos son muy dispersos y, por ende, estos no se encuentran bien distribuidos en las diferentes clases. Pese a esto se optó por mantener dichas distribuciones dado que la idea era asemejar el clasificador lo más posible a la realidad donde los géneros musicales no son parejos y los estilos "Pop" y "Rock" son los que abarcan a un gran porcentaje de las canciones. Lo anterior puede concurrir a un problema de overfitting de los resultados de clasificación el cual fue aceptado por la razón previamente señalada.
A continuación, se ilustrarán los experimentos y resultados realizados para corroborar o descartar la hipótesis postulada a partir de los datos ya procesados.
Experimentación¶
Modelos predictivos¶
El primer conjunto de experimentos realizados consistió en la creación de modelos predictivos de clasificación utilizando los distintos estadígrafos presentes en el dataset. Para evaluar el desempeño de cada uno de los modelos construidos se utilizó el método “Holdout”, donde se reserva 2/3 de los datos para el entrenamiento de los modelos y 1/3 para el testeo de estos.
El primer par de modelos fue construido utilizando todos los estadígrafos presentes en el dataset. Estos entregaron los siguientes resultados:
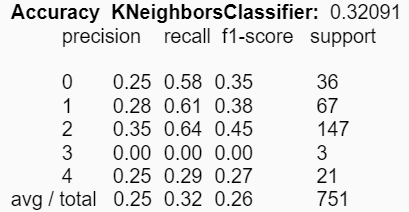 |
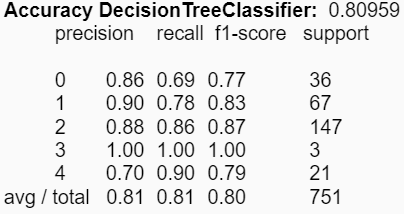 |
|---|---|
Ahora utilizando los estadígrafos min y max para cada uno de los atributos, se obtienes mejoras en la accuracy de KNN, aumentando en aproximadamente 7%:
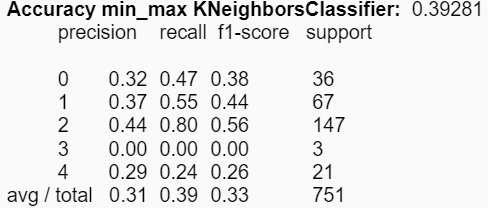 |
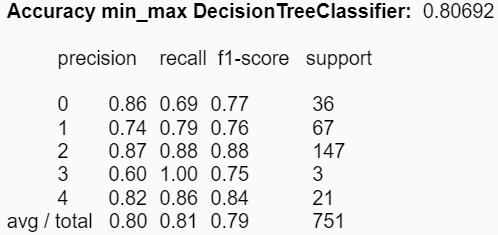 |
|---|---|
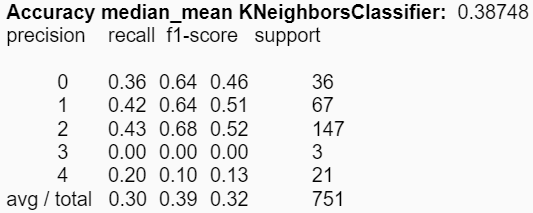
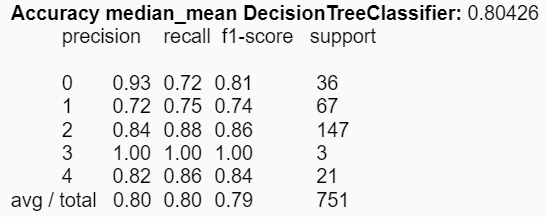
Al utilizar la media y la mediana disminuye levemente la accuracy de KNN:
 |
 |
|---|---|
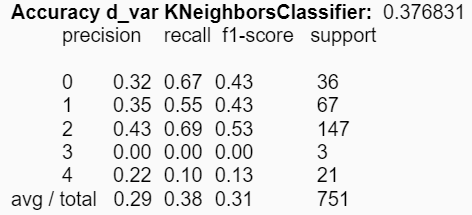
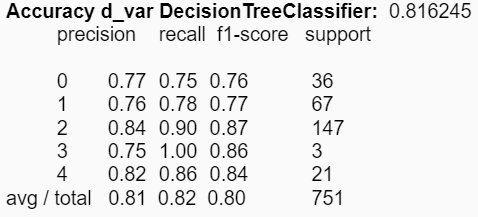
Por último, al utilizar la desviación estándar y la varianza, la accuracy del árbol de decisión aumenta en un 1%:
 |
 |
|---|---|
Clusters¶
Con motivos de comparar el dataset utilizado en este hito con el utilizado en el hito 2, se decidió repetir el experimento de clusterización. Para ello primero se calculó la curva de suma de errores cuadráticos para determinar el número de clusters a utilizar:
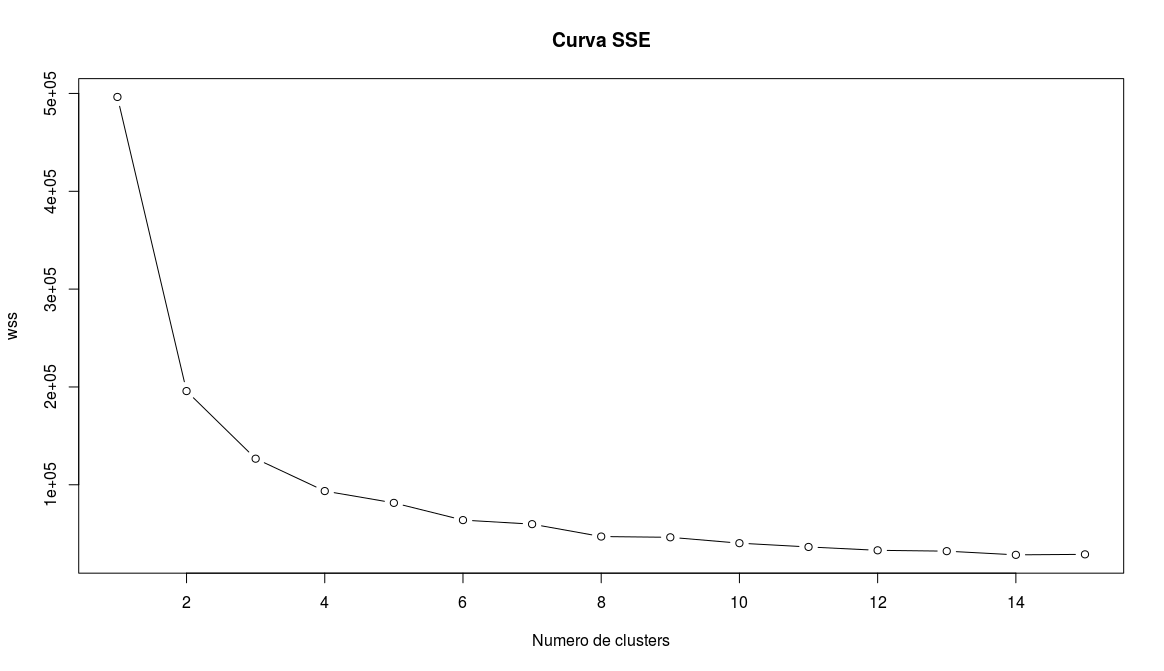
De esta manera utilizando el método del codo, se obtuvo que el número de clusters era 3.
Luego se procedió a realizar clusters mono dimensionales con cada uno de los nuevos parámetros para analizar cómo cada uno de estos particionan el conjunto de datos. Realizando esto se obtuvieron los siguientes resultados:
 |
 |
|---|---|
 |
 |
 |
 |

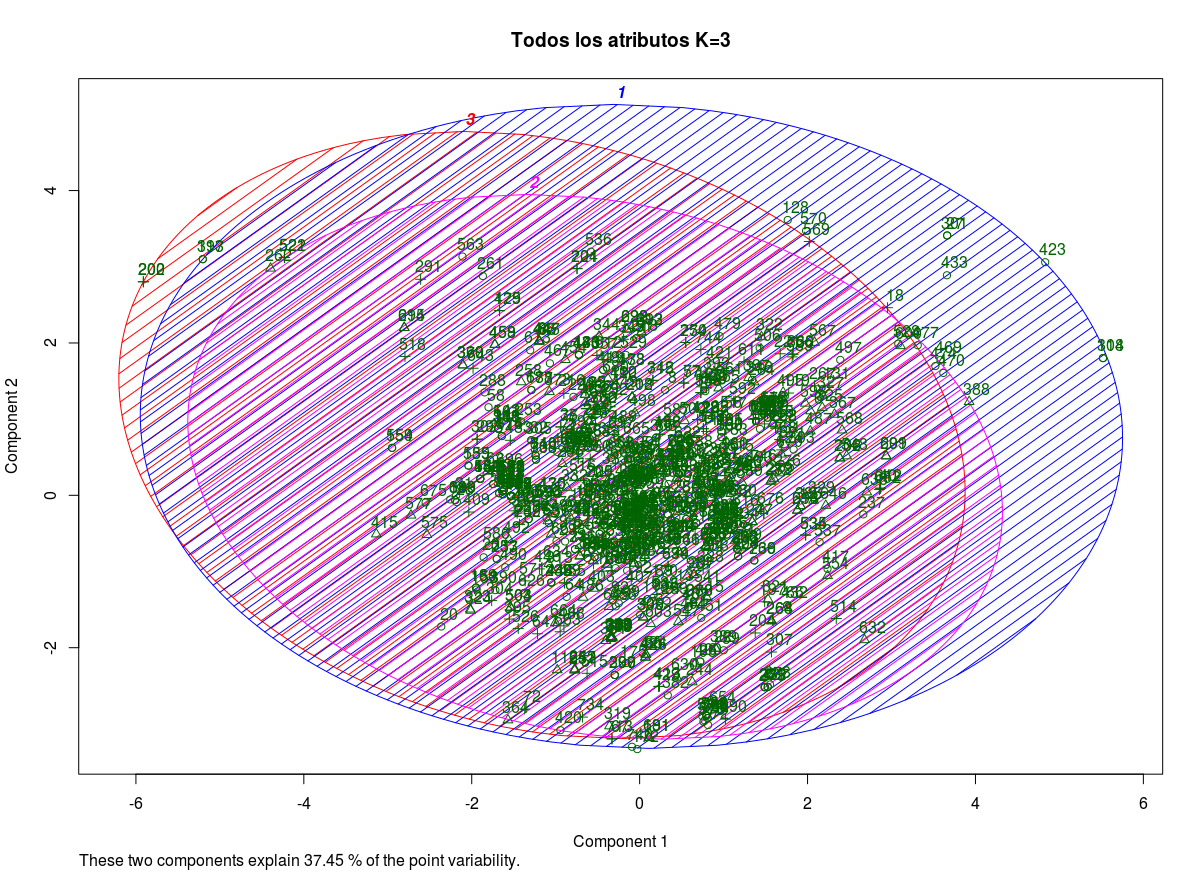
Finalmente se realizó un clúster multidimensional considerando todos los atributos:
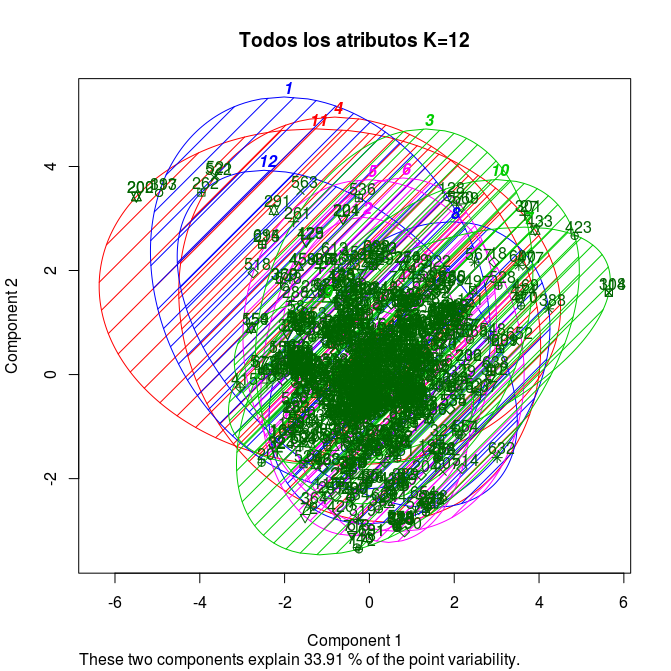
El mismo experimento se repitió, pero utilizando 12 clusters:
Análisis de los resultados¶
Con respecto al conjunto de experimentos asociados a la construcción de modelos, se distinguen diferencias en las reducciones de los atributos respecto a los estadígrafos. Es decir, se pudieron obtener mejores accuracies en los modelos utilizando ciertos estadígrafos, comparado con la utilización de todos de manera simultánea. Para KNN el mejor valor obtenido fue de aproximadamente un 39% utilizando los estadígrafos min y max; y para el árbol de decisión se mejoró el accuracy a un 81% utilizando la desviación estándar y la varianza.
Analizando los resultados obtenidos en el experimento de clusterización se pudo observar que, al igual que en el hito 2, cada uno de los parámetros por su cuenta no es capaz de generar una clara distribución de los géneros entre los clústers. Lo anterior también se ve reflejado al realizar el clúster multidimensional, donde gran parte de los datos se concentran en la intersección de los 3 clúster, no pudiendo apreciarse a que clase pertenecen cada uno de los datos. Por último, al utilizar 12 clúster en vez de 3 se obtienen resultados similares con la excepción de que es más fácil detectar clústers con outliers que se escapan de la concentración central de los datos.
Además, se puede concluir que los métodos de clasificación por agrupación como los son KNN y la clusterización no son los mejores para trabajar con datos estadísticos musicales. Esto se puede ver reflejado a lo largo del proyecto donde no fue posible obtener buenos resultados utilizando clusters y con KNN la mejor accuracy obtenida fue de solo un 39%. En cambio, utilizando el modelo del árbol de decisión se pudo obtener un sobresaliente resultado de un 81% de accuracy utilizando los estadígrafos de la desviación estándar y la varianza.
Finalmente es posible mencionar que, a partir de los resultados obtenidos, la hipótesis planteada anteriormente es descartada dado que es semi-válida, ya que sí es posible clasificar los géneros musicales utilizando las características de Ritmo, Intensidad, Altura, Tono y Timbre mediante el método de clasificación de Árbol de decisión, el cual entregó resultados razonables, pero no es posible clasificar los géneros utilizando los métodos KNN y clustering puesto que estos no entregaron resultados claros.
Trabajo a futuro¶
Con respecto al trabajo a futuro, uno de los primeros puntos a abordar es la agrupación de géneros musicales en una cantidad reducida. El dataset utilizado poseía una gran cantidad de géneros minoritarios (como por ejemplo anime y estudio) que podrían ser incluidos como subgéneros de otros para facilitar la clasificación y el trabajo con los datos.
Asociado al punto anterior se encuentra el problema de equilibrar la cantidad de datos por géneros en el dataset. Este fue un problema que se presentó a lo largo de todo el proyecto, donde los géneros Pop y Rock eran los predominantes entre los datos, lo cual es coherente debido a que son los géneros donde se produce una mayor cantidad de contenido musical. Equilibrando la distribución de los datos entre los géneros se podría evitar un posible overfitting.
Otra manera en que se podrían mejorar los resultados seria la utilización de una mayor cantidad de datos o de ser posible utilizar el dump entero de AcousticBrainz, el cual por problemas de hardware y tiempo solo se logró utilizar una parte de él, resultando en 751 canciones. Además, se podría considerar utilizar otros atributos musicales que estaban presentes en el dataset, que por su complejidad de uso no fueron considerados en el proyecto cómo los son los asociados al espectro de ondas. Estos son vectores que representan la superposición de distintas frecuencias de ondas en una pieza musical.