
UFC es una compañía dedicada a transmitir peleas de MMA por PPV. En cada evento se registra una gran cantidad de información sobre los peleadores, entre los cuales está, récord de peleas, como gano cada pelea, en cuanto tiempo, número de golpes acertados, número de golpes esquivados, entre muchos otros.
En este proyecto buscamos desarrollar un predictor de peleas, además de estudiar diferentes correlaciones entre los atributos de un luchador y cuales son los más importantes a considerar a la hora de escoger un potencial ganador.
El segundo fue creado por nosotros utilizando esta api, la cual recibe el nombre de un competidor y retorna un JSON con su perfil, en este perfil viene información basica del luchador, como su peso, estatura, edad y nacionalidad, pero además contiene el record del competidor, como gano y como perdio cada pelea, número de golpes lanzados, número de golpes exitosos, número de intentos de derribo, número de derribos exitosos. En conjunto con todo esto trae además un resumen de todas las peleas de dicho competidor, en este resumen se incluye, el resultado, el método por el cual terminó la pelea, el round en el que terminó la pelea y el minuto en el que terminó la pelea. Ahora para obtener los nombre de los luchadores usamos otra dataset que contiene los nombres de los luchadores y la misma información basica
Uno de los principales problemas en esta etapa, fue la obtención de los datos, ya que al realizar muchas peticiones desde la misma IP, esta era bloqueada por google, ya que google consideraba que era un posible ataque DOS.
Finalmente se obtuvo información para 1492 luchadores y 31526 peleas, todo esto luego fue traspado a una base de datos MySQL para su manipulación.A continuación se adjunta una imagen del modelo.
Esta etapa es muy importante, porque se debe buscar una adecuada representación de los datos, para que los clasificadores funcionen correctamente. Primero para facilitar la manipulación de los datos se convirtio la altura de pulgadas a centimetros, en conjunto con eso se convirtio la categoría de peso a nominal. Luego con el fin que ningun atributo contribuya más que los otros debido a los rangos que tienen, por ejemplo, el rango de estatura va desde 170 hasta mas de 200, en cambio la edad va desde los 23 hasta los 60, por lo tanto para equiparar esto se normalizo tanto la edad como la estatura.
Luego se procedio a crear un CSV que contiene información de la pelea, atributos del primer competidor y los atributos del segundo competidor, procedimiento para crear este archivo consistio en dada una pelea, obtener la información de la pelea, luego obtener los datos del primer peleador. Este peleador si existe, porque la pelea tiene el id del luchador. En cada pelea tenemos el nombre del oponente, por lo cual para buscar los datos del segundo luchador buscamos por su nombre, el principal problema es que dado un nombre de un luchador, no necesariamente existe en la tabla 'fighters'. Los atributos considerados para el CSV fueron los siguientes:
Los experimentos consistieron en tomar distintos subconjuntos de atributos y probar distintos clasificadores, esto dado que se desconoce cuales atributos son más relevantes. Utilizamos Weka para clasificar. Los clasificadores utilizados fueron los siguientes.
Se crearon 3 subconjuntos de atributos, para probar los clasificadores
En primera instancia se escogieron 14 atributos, con un tratamiento previo básico, en donde se busca que los atributos tengan la correctitud por parte de la nueva tabla creada, la cual se le entrega al clasificador como input para predecir una pelea. Con esto se pretende, evaluar el comportamiento de los clasificadores en una primera aproximación, para luego tratar de mejorar los resultados. Posterior a estas pruebas, se decidió ampliar el dataset, para poder obtener más atributos de mayor valor cualitativo para la predicción de peleas. Además, se realizó una limpieza cuidadosa de los datos, de manera de poder evitar eliminar datos de peleas masivamente, por algún atributo que fuera null. Para solucionar esto, se completaron los datos faltantes con el promedio de los datos que existían, y se normalizó algunos atributos. Con este nuevo conjunto de datos, se procedió a realizar las pruebas con 21 atributos y más de 10.000 registros. Finalmente, se decidió eliminar algunos atributos, cuya información fuera redundante y que cualitativamente no contribuía a predecir mejor una pelea de la ufc. De este modo, se hicieron las pruebas finales con 15 atributos. A continuación se muestran los conjuntos de atributos utilizados para cada experimento:
| Clasificador | TP Rate | Precision | Recall |
|---|---|---|---|
| trees.J48 | 54.6 % | 54.3 % | 54.6 % |
| lazy.IBk | 53.2 % | 52.7 % | 53.2 % |
| functions.SMO | 52.8 % | 52.4 % | 52.8 % |
| bayes.NaiveBayes | 52 % | 54.3 % | 52 % |
| NBTree | 54.5 % | 55 % | 54.5 % |
| bayes.BayesNet | 53 % | 55.4 % | 53 % |
| trees.RandomForest | 59 % | 58.6 % | 59 % |
| Clasificador | TP Rate | Precision | Recall |
|---|---|---|---|
| trees.J48 | 63.1 % | 63.1 % | 63.1 % |
| lazy.IBk | 56.1 % | 56.2 % | 56.1 % |
| functions.SMO | 63.1% | 63.1 % | 63.1 % |
| bayes.NaiveBayes | 60 % | 60.3 % | 60 % |
| NBTree | 63.8 % | 63.8 % | 63.8 % |
| bayes.BayesNet | 63.9 % | 63.8 % | 63.9 % |
| trees.RandomForest | 67.5 % | 67.5 % | 67.5 % |
| Clasificador | TP Rate | Precision | Recall |
|---|---|---|---|
| trees.J48 | 62.4 % | 62.4 % | 62.4 % |
| lazy.IBk | 54.1% | 54.2 % | 54.1% |
| functions.SMO | 62.3% | 62.3 % | 62.3% |
| bayes.NaiveBayes | 57.9 % | 58 % | 57.9 % |
| NBTree | 60.8 % | 60.8 % | 60.8 % |
| bayes.BayesNet | 60.6 % | 60.6 % | 60.6 % |
| trees.RandomForest | 65.7 % | 65.7 % | 65.7 % |
La mayor parte del tiempo del proyecto, fué utilizado para adquirir y limpiar los datos, ya que, los datos se obtienen desde la web (a traves de la api) y se deben generar consultas, con un delay considerable, para evitar ser banneado por las estrictas politicas sobre boots de los servidores a los que se debe acceder. Por otro lado, exiten datos incompletos, y en un formato difícil de tratar, por lo que, limpiar los datos para el correcto funcionamiento del clasificador toma bastante tiempo.
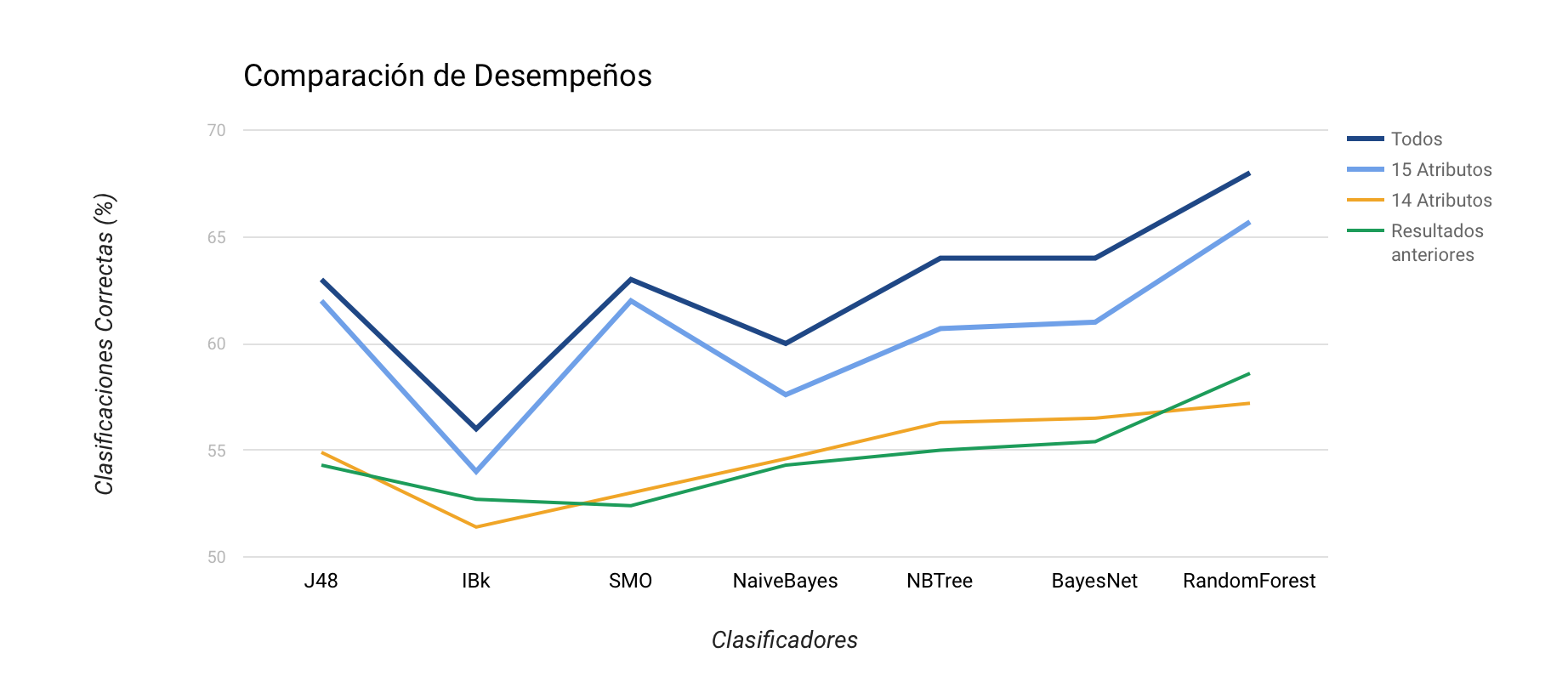
En segundo lugar, es importante señalar que influye considerablemente en los resultados (como se puede apreciar comparando los resultados del experimente 1 con el experimento 3), el cómo se tratan los datos, es decir, como influye que se normalizen, dicretizen y evaluen según su calidad los atributos que se ingresan a los clasificadores. Pues entre el experimento 1 y 3, hay casi la misma cantidad de atributos, pero claramente el experimento 3, posee datos mejor tratados (aplicando a algunas columnas normalización o dicretización), y de mejor calidad (se agregaron los records de cada peleador, con sus batallas ganadas y perdidas).
Además, como se puede apreciar entre el experimento 2 y 3, la cantidad de atributos (21 versus 15) provocó que se comporten de mejor manera los clasificadores con mayor cantidad de atributos. Esto se puede explicar, por un sobre ajuste al clasificador, que puede provocar el hecho de que existan atributos redundantes (tales como año de nacimiento, peso) y atributos irrelevantes como el id asignado al competidor. El clasificador, podría haber creado reglas inválidas que le permitian funcionar mejor con su set de entrenamiento, pero que finalmente se hace en función de información no escencial. En este caso, se ve importante realizar por parte de los desarrolladores del predictor de peleas, un análisis cualitativo de los atributos escogidos, para evitar sobre-ajustes.
Finalmente se pudo observar que el clasificador con mejor comportamiento en todos los experimentos fue RandomForest tree, proporcionado por el software WEKA, con el cual se trabajó.