Descripción del Problema
Desde hace más de 10 años que la plataforma U-Cursos, desarrollada por el Área de Infotecnologías de la Universidad de Chile, se ha ido transformando en una parte cada vez más importante del desarrollo de las actividades universitarias en esta facultad. Su utilidad se refleja tanto en el ámbito académico, al llevar cuenta de las evaluaciones de los distintos ramos y proporcionar espacios de discusión y de almacenamiento de material, como el ámbito de difusión y comunicación, observable en los módulos de novedades, afiches y en el foro institucional.
Dentro de las herramientas de comunicación, el Foro Institucional corresponde a una de las más transversales de la plataforma. Este espacio permite a cualquier integrante de la Facultad publicar un tema u opinar en temas publicados por otras personas, además de poder calificar los temas con un "+1" o un "-1", los cuales poseen un significado variable según el contenido del mensaje inicial. Los temas de los que se tratan en este espacio incluyen actualidad nacional y local, compraventa, objetos perdidos/encontrados, opinión y difusión de eventos de interés general.
La cantidad de tiempo que ha transcurrido desde el lanzamiento del módulo "Foro Institucional" ha permitido la acumulación de más de un millón de mensajes, entre temas y respuestas. A partir de estos mensajes, creemos que es posible determinar el estado anímico de la comunidad, en ciertos periodos y frente a ciertas situaciones recurrentes como periodos de exámenes, paros o situaciones de contingencia nacional.
En primer lugar, se intentará crear un clasificador que permita determinar a partir de un mensaje entregado, si éste posee una carga de sentimientos negativos o si no la posee. Se contrastarán estos datos con distintos periodos temporales, tales como meses del año o horarios del día.
Paralelamente, se encontrarán las palabras más comunes a lo largo de los distintos meses de cada año, de forma de encontrar temas comunes de conversación en el Foro por periodos. Además, se revisará la carga emocional de cada palabra según cuántos mensajes con ella son negativos de acuerdo al clasificador mencionado en el párrafo anterior.
Se concluirá el proyecto evaluando los resultados obtenidos en los pasos anteriores e intentando encontrar alguna correlación interesante. Además, se propondrán ideas que pudiesen haber sido utilizadas para mejorar los resultados o complementarlos, las cuales quedarán propuestas en caso que se desee continuar con la línea de investigación.
(Alguna foto o dibujo de U-cursos)
Descripción de los datos

Los datos con los cuales se trabajó fundamentalmente provienen de una base de datos anonimizada, con todos los mensajes existentes en el Foro Institucional. Cabe destacar que los mensajes del foro pueden ser una respuesta a un mensaje existente, o un mensaje padre que inicia un hilo de conversación. Los dos tipos de mensaje mencionados determinan que cada hilo de conversación esté modelado como un árbol.
En total, la base de datos poseía 1.256.840 mensajes, ingresados a la plataforma en una ventana de tiempo correspondiente a 13 años, desde el 25 de marzo de 2003 hasta el 6 de Mayo del 2016. El mismo equipo del ADI se encargó de anonimizar los datos entregados, asignándole un identificador numérico a cada usuario.
Cada mensaje presente en la base de datos contaba con la siguiente información
- Id del mensaje
- Id anónimo de usuario que crea el mensaje
- Categoría del mensaje (Entre 7 disponibles)
- Título del mensaje
- Mensaje
- Fecha de publicación
- En caso de ser una respuesta, Id del mensaje que está respondiendo
- En caso de ser un mensaje padre, cantidad de +1 y -1
Exploraciones preliminares
A partir de los datos en bruto, es posible hacer algunas exploraciones preliminares.
En primer lugar, es buena idea observar la cantidad absoluta de mensajes publicados por día, a lo largo de los últimos 8 años.
Es posible observar cómo la utilización del foro institucional se disparó a lo largo del año 2011, en especial en el periodo de paro. Desde ese entonces en adelante, la cantidad de mensajes publicados al día ha disminuido paulatinamente.
Para determinar las categorías más populares de la plataforma, se puede observar el siguiente gráfico:
Una comparación a lo largo de los 8 últimos años demuestra que la predominancia de la categoría "Temas Generales" ha sido clara durante todo el periodo.
Otra medida importante que se puede obtener con los datos en bruto es el cálculo de representatividad de los mensajes. ¿Participan todos los usuarios de la plataforma por igual en el Foro Institucional? Los datos del gráfico siguiente corresponden al total de los post emitidos durante el año 2015, donde cada sector circular corresponde a uno de los 11 usuarios que más publicó en el periodo de tiempo anteriormente mencionado:
De un total de 67834 mensajes en el foro durante el año 2015, 6722 de éstos (9,91% del total) fueron aportados por solamente 12 personas de 4094, lo que demostraría que, al menos el año pasado, el Foro Institucional no correspondió a un entorno muy representativo de opiniones.
Finalizada esta exploración y descripción preliminar de los datos, corresponde adentrarse más en ellos, preparándolos para su clasificación según contenido emocional de cada uno de ellos.
Limpieza de los Datos
Para poder elaborar un clasificador de negatividad en los mensajes del Foro, es necesario partir limpiando y seleccionando un conjunto de mensajes con harta información en ellos. Se hacen las siguiente suposiciones sobre los datos:
- Los datos con mayor facilidad para ser clasificados son los mensajes padre, dado que debiesen contener mayor contexto en si mismos que una respuesta a otro mensaje
- Los mensajes más relevantes son los que poseen harta interacción, es decir, muchas respuestas y muchas reacciones del tipo +1/-1
Usando los criterios anteriores, se utilizaron los 10 mil mensajes padre con mayor cantidad de interacciones para clasificarlos manualmente, de forma de utilizarlos posteriormente como input para generar un clasificador de uso general.
Clasificación del conjunto de entrenamiento y prueba
Debido a que en un inicio se consideraba la clasificación completa de los diez mil mensajes, se desarrolló una plataforma de votación en línea para que los mismos usuarios del Foro Institucional particiciparan clasificando, según su criterio, los mensajes escritos en el pasado con el calificativo "negativo" o "no negativo".
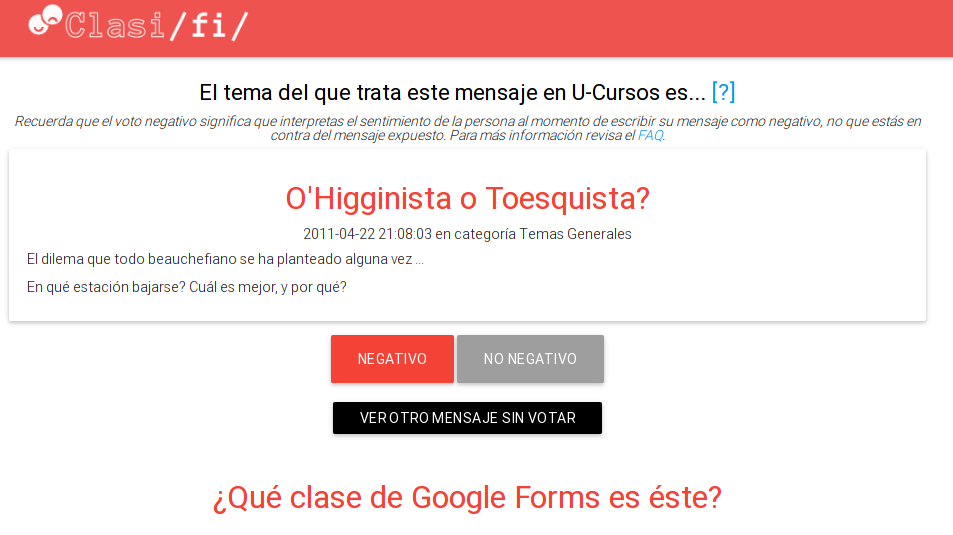
Hubo harta voluntad y motivación en participar de la iniciativa, pero lamentablemente, muchos de los usuarios que colaboraban con la clasificación lo hacían contestando su propia reacción frente al mensaje leído, y no el contenido emocional de éste, lo que hizo necesaria la reclasificación de todos los mensajes.
Finalmente, tras varias horas de trabajo manual, el equipo logró clasificar un poco más de cuatro mil mensajes, de forma de utilizarlos en el entrenamiento del clasificador.
Entrenamiento y resultados del clasificador
Para entrenar el clasificador, se utilizó las librerías numpy y Scikitlearn de Python. En primer lugar, se hizo necesario preprocesar los datos utilizando los algoritmos típicos de clasificación de texto vistos en el curso:
- Se eliminan las Stopwords de cada mensaje
- Se eliminan los Caracteres especiales de cada mensaje
- Se realiza Stemming, es decir, se deja solamente las raíces de las palabras en cada mensaje
En python, el extracto de código que realiza este trabajo (Inspirado en un código entregado por el auxiliar del ramo Aprendizaje Automático Bayesiano) es el siguiente.
import numpy as np import re from nltk.corpus import stopwords from nltk.stem.snowball import SnowballStemmer def preprocess(document): stop = stopwords.words('spanish') # Filtro en español de stopwords regex = re.compile(ur'[^a-zA-Záéíóú]') # Se mantienen solo letras y se remueven los símbolos stemmer = SnowballStemmer('spanish') # Se realiza el stemming de las palabras word_list = document.split() # Se separan las palabras word_list = [word for word in word_list if word not in stop] # Se eliminan las stopwords word_list = [regex.sub('', word) for word in word_list] # Se eliminan los caracteres especiales word_list = [stemmer.stem(word) for word in word_list] # Se hace stemming de las palabras filtered_document = ' '.join(word_list) # Se genera el documento final filtrado return filtered_document
Para realizar el testing y el entrenamiento de forma homogénea se utilizó un k-folding de tipo Stratified con k=5, incluído en la librería mencionada. Paralelamente, se utilizó un clasificador de regresión logística de la librería Scikitlearn para clasificar los mensajes. El código utilizado para este paso es el siguiente:
#!/usr/bin/env python # -*- coding: utf-8 -*- from ProcesarTexto import * from sklearn.metrics import auc, roc_curve from sklearn.linear_model import LogisticRegression from sklearn.cross_validation import StratifiedKFold import numpy as np import time from scipy import interp import pandas as pd print "Leyendo archivo de entrenamiento" trainingFile = "../ucursos/msgs-2-no-pos.csv" db = pd.read_csv(trainingFile) print "archivo de entrenamiento leido" # Los datos están al revés, es decir, el 0 representa "interesting" y el 1 "not interesting". # Se darán vuelta los valores. target = np.array(db.clasif) skf = StratifiedKFold(target, n_folds=5) data = np.array([msg.decode("utf-8") for msg in db.msg]) thresholds = np.linspace(0,1,11) mean_tpr = 0.0 mean_thresh = 0.0 mean_fpr = np.linspace(0, 1, 100) all_tpr = [] tp = 0 fp = 0 tn = 0 fn = 0 for x, (train_index, test_index) in enumerate(skf): print "Generating k-fold ",x t_inicial = time.time() dbTraining, dbTesting = data[train_index], data[test_index] dbTrainingTarget, dbTestingTarget = target[train_index], target[test_index] for i in range(len(dbTraining)): dbTraining[i] = preprocess(dbTraining[i]) t_final = time.time() print "Tiempo de procesamiento (minutos):", (t_final - t_inicial) / 60 # Creación del vector de características cv = CountVectorizer() X_counts = cv.fit_transform(dbTraining) tfidf_transformer = TfidfTransformer() X_tfidf = tfidf_transformer.fit_transform(X_counts) clf = LogisticRegression(class_weight={0:2, 1:0.1}).fit(X_tfidf, dbTrainingTarget) X_new_counts = cv.transform(dbTesting) X_new_tfidf = tfidf_transformer.transform(X_new_counts) proba = clf.predict_proba(X_new_tfidf)[:, 1] fpr, tpr, thresholds = roc_curve(dbTestingTarget, proba) mean_tpr += interp(mean_fpr, fpr, tpr) mean_thresh += interp(mean_fpr, fpr,thresholds) mean_tpr[0] = 0.0 roc_auc = auc(fpr, tpr) plt.plot(fpr, tpr, lw=1, label='ROC fold %d (area = %0.2f)' % (x, roc_auc)) tpi, fpi, tni, fni= confusion(dbTestingTarget, proba, 0.00991040536976) tp += tpi fp += fpi tn += tni fn +=fni plt.plot([0, 1], [0, 1], '--', color=(0.6, 0.6, 0.6), label='Luck') mean_tpr /= len(skf) mean_thresh /= len(skf) print "FPR, TPR => Threshold" for i in range(len(mean_fpr)): print mean_fpr[i],",",mean_tpr[i],"=>",mean_thresh[i] mean_tpr[-1] = 1.0 mean_auc = auc(mean_fpr, mean_tpr) plt.plot(mean_fpr, mean_tpr, 'k--', label='Promedio ROC (area = %0.2f)' % mean_auc, lw=2) plt.xlim([-0.05, 1.05]) plt.ylim([-0.05, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Roc Logistic Regression') plt.legend(loc="lower right") plt.show() print "Final confusion matrix" print "True Positive: ", tp print "False Positive: ", fp print "True Negative:", tn print "False Negative:", fn
Ejecutado el código anterior, se genera una curva ROC que permite ver los resultados de la clasificación.

Se observa que el resultado de la clasificación, a pesar de superar la efectividad de lanzar una moneda, no resulta ser tan buena como se esperaba. A partir de ella, se escoge un umbral que permite seleccionar con eficiencia un 50% de los casos de sentimientos negativos, clasificando erroneamente un 20% de los casos de sentimientos no negativos. Cabe destacar que se hicieron pruebas con otros clasificadores proveídos por la librería utilizada, y que el mejor resultado se obtuvo con el clasificador de regresión logística. La matriz de confusión resultante es la siguiente.
| Real / Predicho | Negativo | No Negativo |
|---|---|---|
| Negativo | 301 | 297 |
| No Negativo | 806 | 2696 |
Accuracy: 73.1%
Precision:27.1%
Recall:50.3%
Considerando que la cantidad inicial de mensajes que se manejaban era bastante grande, se decidió, con el objetivo de disminuir los tiempos de procesamiento, realizar la clasificación de mensajes desde el 2013 en adelante. La cantidad de mensajes que cumple ese criterio corresponde a aproximadamente 282.296 mensajes.
Preprocesamiento en Palabras más comunes
El preprocesamiento en este caso es bastante similar al realizado en la construcción del clasificador, ya que es necesario limpiar los textos de stopwords y caracteres especiales que no califican en la definición de palabra. Se decide no realizar stemming sobre las palabras, de forma de aumentar la exactitud al momento de buscar palabras clave que se repiten.
Se utilizó R para realizar el conteo de las palabras que más se repiten según mes, separándolas en cantidad de publicaciones negativas y no negativas que las contienen. El código que realizó este trabajo es el siguiente.
library("tm") library("e1071") library("RTextTools") # Mensajes M <- read.csv("C:/Users/cristobal/Desktop/ucursos66_classified.csv", encoding="UTF-8", header=TRUE) vectortotal<-c() first<-substring(M[1,4],6,7) i<-1 inicio<-1 #separando por mes mes<-seq(1,12,1) for(kk in mes){ while(first==substring(M[i,4],6,7)) i<-i+1 MS<-M[inicio:i, ] first=substring(M[i,4],6,7) inicio<-i #review_text <- paste(MS$text, collapse=" ") review_source <- VectorSource(MS) corpus <- Corpus(VectorSource(MS$msg)) corpus <- tm_map(corpus, content_transformer(tolower)) corpus <- tm_map(corpus, removePunctuation) toSpace <- content_transformer(function(x, pattern) { return (gsub(pattern, " ", x))}) corpus <- tm_map(corpus, toSpace, "-", lazy = T) corpus <- tm_map(corpus, toSpace, ":", lazy = T) corpus <- tm_map(corpus, toSpace, "\"", lazy = T) corpus <- tm_map(corpus, toSpace, "\\�", lazy = T) corpus <- tm_map(corpus, toSpace, "\\?", lazy = T) corpus <- tm_map(corpus, toSpace, "�", lazy = T) corpus <- tm_map(corpus, toSpace, "�", lazy = T) corpus <- tm_map(corpus, removeNumbers, lazy = T) corpus <- tm_map(corpus, removeWords, stopwords("spanish"), lazy = T) corpus <- tm_map(corpus, stripWhitespace) a.dtm1 <- DocumentTermMatrix(corpus, control = list(wordLengths = c(3,10))) N <- 150 common<-findFreqTerms(a.dtm1, N) j<-length(common)-1 if(j>1){ c<-seq(1, j-1, 1) totalneg<-0 totalpos<-0 noneg<-0 neg<-0 vector<-c() for (num in c){ k<-1 for (mensj in MS$msg){ if(regexpr(common[num], mensj)!=-1){ if(MS[k,5]==0){ totalpos<-totalpos+1 } if(MS[k,5]==1){ totalneg<-totalneg+1 } if(num==1){ if(MS[k,5]==0){ noneg<-noneg+1 } if(num==1){ neg<-neg+1 } } } k<-k+1 } k<-1 vector <- c(vector,common[num] ) vector <- c(vector,totalpos ) vector <- c(vector,totalneg ) vector totalneg<-0 totalpos<-0 } } vectortotal<-c(vectortotal,paste(c("Mes ", kk), collapse = " ")) vectortotal<-c(vectortotal,paste(c("negativos ", neg), collapse = " ")) vectortotal<-c(vectortotal,paste(c("positivos ", noneg), collapse = " ")) vectortotal<-c(vectortotal,vector) print("mes") } write.csv(vectortotal, file ="myfile4.csv", row.names=FALSE)
Exploración de los datos
Con los datos ya procesados y el clasificador ya utilizado, se exploraron los datos obtenidos por ambos procesamientos.
Clasificador de Negatividad
Se analizó la negatividad de los mensajes en el Foro desde el 2013 hasta el 2015 en dos intervalos distintos:
- Intervalos mensuales
- Intervalos horarios
Los resultados fueron los siguientes:
En el caso de los meses, se observa una proporción bastante similar a lo largo del año, salvo por unos puntos levemente más altos en junio, a fin de año y en febrero.
En el caso de las horas, se observa que la razón de negatividad en los mensajes es constante, salvo en las noches, donde aumenta de forma perceptible a las 2:00 AM y a las 5:00 AM. También se observa una disminución en el promedio cerca de las 8:00AM.
Palabras más comunes
Al momento de generar la lista de palabras más comunes, saltó un problema inesperado. Muchas de las palabras más repetidas correspondían a palabras muy comunes en el contexto en que se utiliza el Foro Institucional. Otras palabras semejaban stopwords, pero no habían sido removidas por el trozo de código encargado de ésto. Palabras como "Beauchef", "Así", "Cosas", "Creo" llenaban la lista en cada mes, revelando los términos a los que estamos más acostumbrados y algunas muletillas que nos pegamos entre nosotros.
Luego de analizar la lista generada, el equipo consideró que la información más ilustrativa que se podía entregar correspondía a caracterizar los tres años de datos utilizando las palabras clave que más se repetían en todos los meses. De esta forma, se podía visualizar las palabras más importantes en general en el foro.
La siguiente imagen, generada en WordCloud, corresponde a una nube de palabras clave, en la cual las palabras aparecen en un mayor tamaño si es que éstas fueron las más utilizadas durante una mayor cantidad de meses. Se observan los términos mencionados unos párrafos atrás y algunos más.

Resultados
A partir de los resultados obtenidos en las fases anteriores, es posible llegar a varias conclusiones distintas, relacionadas con el conjunto de datos utilizado, el dominio en el cual se trabajó y el problema principal que se buscaba resolver.
Algunas observaciones
En primer lugar, es muy importante notar que, a partir de lo observado en el análisis de mensajes del 2015, se puede apreciar que los datos obtenidos a partir del foro institucional no son representativos del total de personas integrantes de la comunidad beauchefiana.
En segundo lugar, los valores de prueba obtenidos para el clasificador (Tanto la curva ROC como la matriz de confusión final utilizada) muestran que el clasificador deja que desear al momento de hacer su trabajo. Su calidad influye directamente en los resultados que se obtienen desde su entrenamiento en adelante.
Considerando los valores obtenidos en la etapa final de exploración de datos como cercanos a la realidad, se pueden observar comportamientos entendibles y coherentes con la realidad. Una mayor negatividad en el foro en horas de la madrugada puede deberse al mismo desvelo de estar despierto a altas horas de la noche, o a los motivos, posiblemente relacionados con la misma Universidad, que lo tienen en ese estado. Otra explicación para este fenómeno correspondería a que la cantidad de mensajes en esos horarios es bastante baja, por lo cual el margen de error en la clasificación se hace más notorio.
En el caso de la negatividad por meses del año, se comprende que ésta se concentre principalmente hacia los fines de semestre y un poco antes de inicio de las clases. Otra explicación para la negatividad en febrero es similar a la dada en el caso horario, dado que en ese mes la cantidad de mensajes es mucho menor a la que hay en periodo de clases.
Por último, las palabras más comunes para cada mes permitieron analizar desde otra perspectiva el contenido existente en el Foro Institucional, dándole contexto a la clasificación realizada en la primera parte y permitiendo, con algún trabajo posterior, perfeccionarlo según los significados de las mismas palabras.
Seguridad y Privacidad de los datos
Es un tema de interés la privacidad de los datos al momento de analizar información relacionada directamente con usuarios de una plataforma. A pesar que los identificadores de los mensajes se encontraban anonimizados en la base de datos, basta con una búsqueda del cuerpo del mensaje en el buscador de U-Cursos para encontrar al creador de un mensaje en pocos minutos.
El lado positivo es que la única forma de acceder al buscador de U-cursos en el Foro Institucional es teniendo una cuenta de usuario, la misma que serviría en un principio para poder haber leido el mensaje en cuestión. Por lo tanto, siempre y cuando no se divulguen los autores desde dentro del mismo sitio, se puede considerar que los mensajes no tienen forma de ser relacionados con una persona de forma directa.
Conclusiones y Problemas Pendientes
A partir de las observaciones anteriores, se plantean las siguientes conclusiones y problemas pendientes.
- La información contenida en el Foro Institucional de U-Cursos nos permite analizar el estado anímico de un conjunto acotado de gente, no siendo representativo de los miles de estudiantes, funcionarios y profesores que conviven día a día en la facultad.
- Algunas de las palabras obtenidas como comunes para ciertos periodos son demasiado genéricas dentro del dominio en el que se está trabajando (Por ejemplo, beauchef o alumno) o corresponden a stopwords un poco más rebuscadas que las que posee la librería utilizada (Por ejemplo, algún) . Se propone crear un diccionario personalizado de stopwords que consideren las palabras más repetidas del entorno en el que se ejecuta la aplicación.
- Dejando de lado lo anterior, las palabras rescatadas y útiles de cada mes pueden llegar a ser el reflejo de distintos temas que se están discutiendo en forma real en el periodo de tiempo correspondiente. Esta información puede ser bastante útil para tener en cuenta las necesidades y las inquietudes del grupo que sí es representado por los mensajes del Foro Institucional.
- El equipo propone como mejoras al clasificador la utilización de emoticones en los mensajes como features para mejorar los resultados, dado que no se alcanzó a implementar esa idea. Otra propuesta interesante es la de comprarar con un clasificador construído solamente con palabras clave positivas y negativas.
- En conclusión, el trabajo desarrollado en este informe permitió al equipo acercarse de forma más real al trabajo con grandes conjuntos de datos, notando la alta complejidad que esto requiere. Se considera esta experiencia como una parte importante del proceso de formación como profesional, y en especial como punto de partida para distintos trabajos con grandes cantidades de datos que se pudiesen realizar en el futuro.